


What is torch.nn(Neuron Network)?
•
PyTorch에서 신경망을 구성하고 학습하는 데 필요한 여러 도구들을 제공하는 매우 중요한 모듈
•
딥러닝 모델을 만들 때 필요한 레고 블록처럼, 신경망을 구성하는 다양한 구성 요소들을 제공해주는 역할
신경망 (Artificial Neural Network, ANN)
•
신경망은 뉴런(neuron)/노드(node)로 구성되며, 이들이 서로 연결된 형태를 가진다.
신경망의 동작 방식
•
입력 데이터를 받아 여러 층을 거쳐서 출력값을 생성하는 것
•
입력 데이터 전파(Forward Propagation):
◦
입력층에서 입력 데이터를 받아들이고, 이를 은닉층을 통해 순차적으로 처리한다.
◦
각 뉴런에서는 **가중치(weight)**와 **편향(bias)**를 적용한 선형 연산이 일어나며, 이를 **활성화 함수(activation function)**를 통해 비선형 변환을 거친다.
◦
이러한 과정이 여러 은닉층을 통과하며 반복되고, 최종적으로 출력층에서 예측값이 나온다.
•
오차 계산:
◦
출력층의 예측값과 실제 값(라벨) 간의 차이를 계산하여, **손실 함수(loss function)**를 통해 오차를 구한다.
◦
오차가 크다면, 신경망의 가중치와 편향을 수정할 필요가 있다.
•
역전파(Backward Propagation):
◦
역전파는 오차를 기반으로 각 가중치에 대한 기울기를 계산하고, 이를 통해 가중치를 업데이트하는 과정이다.
◦
이때, 기울기 하강법(Gradient Descent) 같은 최적화 알고리즘을 사용하여 가중치를 조금씩 조정한다.
◦
이 과정이 반복되면서 신경망은 점차 학습되어 오차가 줄어들고, 더 정확한 예측을 하게 된다.
신경망의 유형
1.
단층 퍼셉트론(Single Layer Perceptron):
•
하나의 은닉층이 없는 신경망으로, 매우 간단한 패턴만 학습할 수 있다.
•
XOR 문제와 같은 복잡한 패턴을 학습하는 데는 한계가 있다.
2.
다층 퍼셉트론(Multi-layer Perceptron, MLP):
•
여러 개의 은닉층을 포함한 신경망으로, 복잡한 데이터 패턴을 학습할 수 있다.
•
일반적으로 딥러닝(Deep Learning)이라는 용어는 은닉층이 여러 개 있는 신경망을 지칭
3.
합성곱 신경망(Convolutional Neural Network, CNN):
•
주로 이미지 처리에 사용되며, 이미지의 국소적 특징을 추출하는 데 유리한 구조
•
합성곱 레이어와 풀링 레이어를 통해 이미지의 공간 정보를 압축하고 중요한 특징을 학습한다.
4.
순환 신경망(Recurrent Neural Network, RNN):
•
시계열 데이터나 순차 데이터를 처리하는 데 특화된 신경망
•
시간적 연속성이 있는 데이터에서 과거 정보가 현재 예측에 영향을 줄 수 있도록 설계되었다.
•
RNN의 변형인 LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)는 장기 의존성을 더 잘 학습할 수 있다.
신경망의 장점과 단점
•
장점
1.
복잡한 패턴 학습: 신경망은 선형 모델로는 학습하기 어려운 복잡한 데이터 패턴을 잘 학습할 수 있다.
2.
범용성: 이미지, 음성, 텍스트 등 다양한 형태의 데이터를 처리하는 데 강력하다.
3.
비선형성: 활성화 함수를 통해 비선형성을 도입하여, 선형 변환만으로는 해결할 수 없는 문제를 풀 수 있다.
•
단점
1.
많은 데이터 요구: 신경망이 잘 학습되려면 대규모 데이터셋이 필요하다.
2.
과적합 위험:
•
데이터가 적거나 모델이 너무 복잡할 경우 과적합(overfitting)이 발생할 수 있다.
→ 이를 방지하기 위해 드롭아웃(Dropout) 같은 기법을 사용
3.
학습 속도
•
신경망은 학습 과정에서 많은 연산이 필요하므로, 훈련 속도가 느릴 수 있다.
•
특히, 매우 깊은 신경망에서는 학습 시간이 오래 걸릴 수 있다.
→ 그래서 GPU를 사용
레이어
•
신경망(Neural Network)의 핵심 구성 요소 중 하나
•
데이터를 입력받아 여러 계산을 수행한 뒤 출력값을 반환하는 연산(계산) 단위
•
신경망은 여러 개의 레이어가 연결된 구조로 되어 있으며, 입력 데이터를 처리하고 특징을 추출하여 최종 예측을 할 수 있도록 한다.
•
각 레이어는 입력을 받아 가중치(weight)와 편향(bias)을 적용한 뒤, 활성화 함수(activation function)를 사용하여 비선형적인 출력을 생성
정규화
nn.Module
•
설명
◦
nn.Module은 모든 신경망 레이어(layer)와 모델의 기본 클래스다. 즉, 신경망의 블록들을 만들어내는 틀 역할
◦
nn.Module을 상속받아 새로운 신경망 모듈을 만들 수 있다.
◦
대부분의 PyTorch 모델은 이 클래스를 상속하여 만들어진다.
•
특징
◦
forward() 메서드를 사용해 데이터가 어떻게 처리될지를 정의하고, 그 외에도 학습 가능한 파라미터(가중치 등)를 자동으로 관리한다.
•
예시
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2) # 다시 절반으로 줄임
)
def forward(self, x):
x = self.layer1(x)
return x
Python
복사
주요 정의 메서드
__init__(self)
•
모델의 레이어를 정의하는 부분.
•
신경망의 레이어나 필요한 변수를 초기화하는 데 사용된다. 모델의 구조를 이곳에서 정의한다.
•
예시
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(10, 20) # 10개의 입력, 20개의 출력
self.relu = nn.ReLU() # 활성화 함수
self.fc2 = nn.Linear(20, 1) # 20개의 입력, 1개의 출력
Python
복사
forward(self, x)
•
입력 데이터가 어떻게 네트워크를 통과할지를 정의하는 메서드
•
입력 데이터가 모델을 통해 전달되는 과정을 정의한다.
•
이 메서드는 신경망이 순방향으로 데이터를 처리하는 방식(순전파)을 설명한다.
•
예시
def forward(self, x):
x = self.fc1(x) # 첫 번째 선형 레이어를 통과
x = self.relu(x) # ReLU 활성화 함수 적용
x = self.fc2(x) # 두 번째 선형 레이어를 통과
return x
Python
복사
핵심 메서드
to()
•
모델을 GPU나 CPU로 이동시킬 때 사용된다.
•
예를 들어, 모델을 GPU에서 학습하려면 to() 메서드를 사용하여 모델과 데이터를 GPU로 옮겨야 한다.
device = 'cuda'
model = MyModel().to(device) # 모델을 GPU로 이동
Python
복사
eval()
•
모델을 평가 모드로 전환한다.
•
드롭아웃(Dropout)이나 배치 정규화(BatchNorm) 같은 레이어들은 학습 모드와 평가 모드에서 다르게 동작하므로, 평가할 때는 eval()로 설정해야 한다.
model.eval() # 모델을 평가 모드로 전환
Python
복사
train() : 기본값
•
모델을 학습 모드로 전환한다.
•
기본적으로 모델은 학습 모드로 설정되지만, 평가 후 다시 학습을 할 때는 train()으로 설정해주어야 한다.
model.train() # 모델을 학습 모드로 전환
Python
복사
레이어(Layer)
nn.Sequential
•
설명
◦
여러 레이어를 순차적으로 쌓아 간단하게 모델을 구성할 수 있게 해주는 모듈
◦
각 레이어를 순서대로 연결해 모델을 정의하는 경우 유용하다.
•
용례: 간단한 네트워크를 정의할 때 매우 편리하다.
•
순서대로 레이어를 정의한다.
model = nn.Sequential(
nn.Linear(10, 20),
nn.ReLU(),
nn.Linear(20, 5)
)
Python
복사
nn.Linear (선형 레이어)
•
설명
◦
입력과 출력 사이의 선형 변환을 수행하는 레이어
◦
즉, 입력 데이터를 특정 가중치와 곱하고 편향을 더해 결과를 도출한다.
•
메소드: nn.Linear(in_features, out_features)
◦
in_features: 입력 데이터의 크기
◦
out_features: 출력 데이터의 크기
•
용례: Fully Connected Layer(완전 연결 층)에서 주로 사용된다. = Dense Layer
•
사용 용도: 회귀 문제, 분류 문제 등에서 많이 사용된다.
•
예제 코드
linear = nn.Linear(10, 5) # 입력 크기 10, 출력 크기 5
Python
복사
nn.Conv{}d (D 합성곱 레이어)
•
설명
◦
n차원 데이터를 처리하는 합성곱 레이어
◦
이미지의 공간 정보를 유지하며 특징을 추출할 때 사용
•
메소드:
◦
nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0)
▪
in_channels: 입력 채널 수 (예: 단어 임베딩의 크기 또는 시계열 데이터의 채널 수)
▪
out_channels: 출력 채널 수 (필터 개수)
▪
kernel_size: 합성곱 커널(필터)의 크기 (예: 3은 한 번에 3개의 값을 처리)
▪
stride: 커널이 이동하는 간격 (기본값은 1, 값을 크게 하면 특성 크기 축소)
▪
padding: 입력 데이터 가장자리에 추가하는 값 (입력을 더 크게 만들어 정보 손실을 방지)
▪
추가 옵션
•
dilation: 커널의 크기를 확장하여 넓은 범위에서 특징을 추출할 수 있음.
•
groups: 입력과 출력 채널을 그룹으로 나누어 처리하는 옵션
(default: 1, 모든 채널 처리).
•
bias: 편향 값 사용 여부 (기본값은 True).
◦
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
▪
in_channels: 입력 채널 수 (예: RGB 이미지라면 3, 흑백 이미지라면 1)
▪
out_channels: 출력 채널 수 (필터의 개수)
▪
kernel_size: 합성곱 커널의 크기 (예: (3, 3)은 3x3 크기의 필터)
▪
stride: 커널이 이동하는 간격 (기본값 1, 값이 크면 출력 크기 축소)
▪
padding: 입력 데이터 가장자리에 추가하는 값 (필터가 경계까지 적용되도록 함)
▪
추가 옵션
•
dilation: 커널의 크기를 확장하여 더 넓은 영역을 학습 (기본값 1).
•
groups: 채널을 그룹으로 나누어 처리
(예: groups=2이면 2개의 그룹으로 나누어 학습).
•
bias: 편향 값을 추가할지 여부 (기본값은 True).
◦
nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0)
▪
in_channels: 입력 채널 수 (예: 3D 의료 영상 데이터라면 채널 수)
▪
out_channels: 출력 채널 수 (필터의 개수)
▪
kernel_size: 3차원 합성곱 커널의 크기 (예: (3, 3, 3)은 3x3x3 필터)
▪
stride: 커널이 이동하는 간격
(기본값 1, 값을 크게 하면 계산 속도는 빨라지지만 출력 크기 축소)
▪
padding: 입력 데이터 가장자리에 추가하는 값
(정보 손실을 방지하기 위해 경계에서 패딩을 추가)
▪
추가 옵션
•
dilation: 커널의 확장 정도 (확장된 커널은 더 넓은 영역에서 특징 추출).
•
groups: 채널을 그룹으로 나누어 처리 (default: 1, 모든 채널 처리).
•
bias: 편향 값 사용 여부 (기본값은 True).
•
용례
◦
1D : 시계열 데이터나 연속적인 데이터에서 사용
◦
2D : 이미지 처리(컴퓨터 비전)에서 사용
◦
3D : 비디오 데이터나 3차원 데이터(의료 3D 스캔 데이터, 점 구름 데이터 처리) 를 처리
•
사용 용도: 이미지 분류, 객체 탐지, 이미지 생성 등.
•
예제 코드
conv = nn.Conv2d(3, 16, 3, stride=1, padding=1) # 입력 채널 3, 출력 채널 16, 커널 크기 3x3
Python
복사
nn.MaxPool2d (최대 풀링: 차원축소 레이어)
•
설명
◦
합성곱 층에서 추출한 특징 맵을 다운샘플링하는 역할
◦
주어진 영역에서 가장 큰 값을 선택해 출력한다.
◦
계산량을 줄인다.
•
메소드: nn.MaxPool2d(kernel_size, stride=None, padding=0)
◦
kernel_size: 풀링을 할 영역의 크기
◦
stride: 이동 간격 (지정하지 않으면 kernel_size와 동일)
◦
padding: 입력의 가장자리에 추가하는 값
•
용례: 이미지 데이터의 크기를 줄이고 특징을 요약할 때 사용된다.
•
사용 용도: 이미지 처리에서 주로 사용
•
예제 코드
maxpool = nn.MaxPool2d(2, 2) # 2x2 영역에서 최대값을 선택, stride 2
Python
복사
nn.BatchNorm2d (배치 정규화 레이어)
•
설명
◦
입력 데이터를 정규화해 학습 속도를 빠르게 하고, 모델의 일반화 성능을 높이는 데 사용한다.
•
메소드: nn.BatchNorm2d(num_features)
◦
num_features: 입력의 채널 수
•
용례: 합성곱 신경망(CNN)에서 자주 사용된다.
•
사용 용도 : 과적합을 방지하고 모델의 학습을 안정화할 때 유용
•
예제 코드
batchnorm = nn.BatchNorm2d(16) # 채널 수 16개
Python
복사
nn.Dropout (드롭아웃 레이어)
•
설명: 학습 과정에서 일부 뉴런을 랜덤하게 비활성화해 과적합을 방지하는 데 사용
•
메소드: nn.Dropout(p=0.5)
◦
p: 드롭아웃 비율 (0과 1 사이의 값, 0.5는 50%의 뉴런을 비활성화함)
•
용례: 과적합을 방지하기 위해 신경망의 중간에서 자주 사용된다.
•
사용용도: 과적합이 발생할 위험이 있는 복잡한 모델에서 많이 사용된다.
•
예제 코드
dropout = nn.Dropout(0.5)
Python
복사
nn.LSTM (Long Short-Term Memory, LSTM 레이어)
•
설명: 순환 신경망(RNN)의 한 종류로, 시계열 데이터를 처리할 때 장기 의존성을 기억할 수 있는 레이어다.
•
메소드: nn.LSTM(input_size, hidden_size, num_layers)
◦
input_size: 입력 데이터의 크기
◦
hidden_size: LSTM의 은닉 상태 크기
◦
num_layers: LSTM 레이어의 수
•
용례: 자연어 처리, 시계열 분석 등에서 주로 사용된다.
•
주로 사용되는 문제: 자연어 처리, 시계열 데이터 예측.
•
예제 코드
lstm = nn.LSTM(10, 20, 2) # 입력 크기 10, 은닉 상태 크기 20, 2개의 LSTM 레이어
Python
복사
nn.Embedding (임베딩 레이어)
•
설명: 정수 인덱스를 임베딩 벡터로 변환하는 레이어로, 주로 텍스트 데이터에서 단어를 벡터로 변환하는 데 사용된다.
•
메소드: nn.Embedding(num_embeddings, embedding_dim)
◦
num_embeddings: 임베딩할 단어의 개수
◦
embedding_dim: 임베딩 벡터의 크기
•
용례: 자연어 처리에서 단어를 벡터로 변환할 때 자주 사용된다.
•
주로 사용되는 문제: 텍스트 데이터를 벡터화할 때 자주 사용.
•
예제 코드
embedding = nn.Embedding(1000, 64) # 1000개의 단어, 임베딩 크기 64
Python
복사
nn.Flatten (평탄화 레이어)
•
설명
◦
입력 텐서를 1차원 벡터로 변환하는 레이어
◦
CNN과 같은 네트워크에서 Convolutional Layer의 출력을 Fully Connected Layer로 입력할 때 주로 사용한다.
◦
다차원 텐서를 하나의 연속된 차원으로 평탄화하여 인공 신경망의 선형 계층에 연결하기 쉽게 만들어준다.
•
메소드: nn.Flatten(start_dim=1, end_dim=-1)
◦
start_dim: 평탄화할 시작 차원을 지정 (기본값은 1).
◦
end_dim: 평탄화할 마지막 차원을 지정 (기본값은 -1, 즉 마지막 차원까지).
•
용례: 컨볼루션 연산 이후 결과를 선형 레이어에 넣기 전에 사용된다. 예를 들어, 2D 이미지의 출력 텐서를 1D 벡터로 변환할 때 사용된다.
•
사용 용도: 컨볼루션 층에서 추출한 특징 맵을 선형 레이어로 전달할 때, 이를 일차원 벡터로 변환하기 위해 사용된다.
•
예제 코드
flatten = nn.Flatten()
SQL
복사
nn.Embedding (임베딩 레이어)
•
설명
◦
정수 인덱스를 고정된 크기의 밀집 벡터로 변환하는 레이어.
◦
주로 자연어 처리에서 단어를 벡터 표현으로 바꾸기 위해 사용된다. 입력으로 단어의 인덱스를 받아 그 인덱스에 해당하는 임베딩 벡터를 반환한다.
◦
임베딩은 학습 가능한 레이어로, 단어 간의 의미적 유사성을 학습해 벡터 공간에서 이를 반영할 수 있다.
•
메소드: nn.Embedding(num_embeddings, embedding_dim)
◦
num_embeddings: 단어 사전의 크기 (전체 단어의 개수).
◦
embedding_dim: 각 단어를 표현하는 벡터의 차원 (임베딩 벡터의 크기).
•
용례: 단어를 정수로 표현한 뒤, 이를 벡터로 변환해 신경망에 입력하는 경우에 사용된다. 주로 자연어 처리(NLP) 모델에서 단어 임베딩을 생성하기 위해 많이 사용된다.
•
사용 용도: 텍스트 데이터 처리 시 단어 또는 문장을 임베딩 벡터로 변환해 모델의 입력으로 사용하기 위해 사용된다. 이를 통해 단어의 의미를 벡터 공간에서 다룰 수 있다.
•
예제 코드:
embedding = nn.Embedding(100, 10)
SQL
복사
Transformer Layers
nn.TransformerEncoderLayer
•
d_model: 기본값이 512
•
nhead: 기본값이 8
•
dim_feedforward: 기본값이 2048
•
batch_first: 기본값이 False
nn.TransformerEncoder
•
encoder_layer: TransformerEncoderLayer의 객체
•
num_layers: 인수로 전달 받은 인코더 레이어를 얼마나 쌓을 것인가의 수
트랜스포머 모델의 주요 파라미터
•
d_model: 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미합니다. (default=512)
•
num_encoder_layers: 트랜스포머 모델에서 인코더가 총 몇 층으로 구성되었는지를 의미합니다. (default=6)
•
num_decoder_layers: 트랜스포머 모델에서 디코더가 총 몇 층으로 구성되었는지를 의미합니다. (default=6)
•
nhead: 멀티헤드 어텐션 모델의 헤드 수, 어텐션을 사용할 때 여러 개로 분할해서 병렬로 어텐션을 수행하고 결과값을 다시 하나로 합치는 방식에서 병렬의 수 (default=8)
•
dim_feedforward: feedforward network model 의 차원, 피드 포워드 신경망의 은닉층의 크기(default=2048).
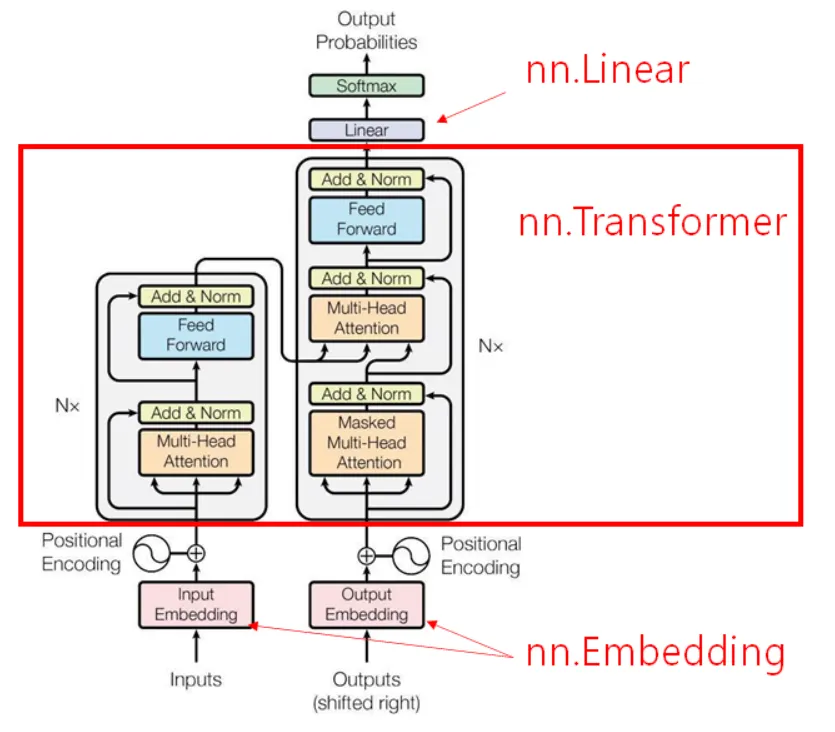
함수
nn.ReLU (비선형 활성화 함수)
•
설명
◦
비선형 활성화 함수 중 하나
◦
입력 값이 0보다 크면 그대로 반환하고, 0 이하이면 0으로 만든다.
◦
신경망에 비선형성을 부여해 복잡한 패턴을 학습하게 도와준다.
•
용례
◦
대부분의 딥러닝 모델에서 매우 자주 사용
◦
특히 깊은 신경망에서는 필수적인 활성화 함수
•
주요 파라미터
◦
inplace: True로 설정하면 입력 데이터를 덮어쓰기 방식으로 변환하여 메모리 사용을 줄일 수 있다. 기본값은 False.
relu = nn.ReLU() # 대체론 이렇게
# or
relu = nn.ReLU(inplace=True)
Python
복사
nn.CrossEntropyLoss (손실 함수)
•
설명
◦
분류 문제에서 자주 사용하는 손실 함수
◦
모델의 예측 값과 실제 라벨 간의 차이를 계산해 모델을 학습시키는 데 사용
◦
이 함수는 모델의 예측 확률 분포와 실제 라벨을 비교해 손실을 계산
•
용례
◦
이진 분류나 다중 클래스 분류 문제에서 사용되며, 모델이 틀린 예측을 할 때 더 큰 손실 값을 반환해 이를 학습 과정에서 줄이도록 돕는다.
•
주요 파라미터
◦
weight: 각 클래스에 대해 가중치를 부여할 때 사용. 클래스의 비율이 불균형한 경우 유용.
◦
reduction: 손실 값을 어떻게 처리할지 결정하는 파라미터. mean은 손실 값을 평균내고, sum은 합을 구하며, none은 별도의 처리 없이 그대로 반환.
loss_fn = nn.CrossEntropyLoss(weight=None, reduction='mean')
Python
복사
