•
자동화된 기계 학습(AutoML)은 기계 학습을 데이터에 적용하는 프로세스를 자동화한다.
•
데이터 세트가 있는 경우 AutoML을 실행하여 다른 데이터 변환, 기계 학습 알고리즘, 하이퍼 매개 변수에 대해 반복하여 최상의 모델을 선택할 수 있다.
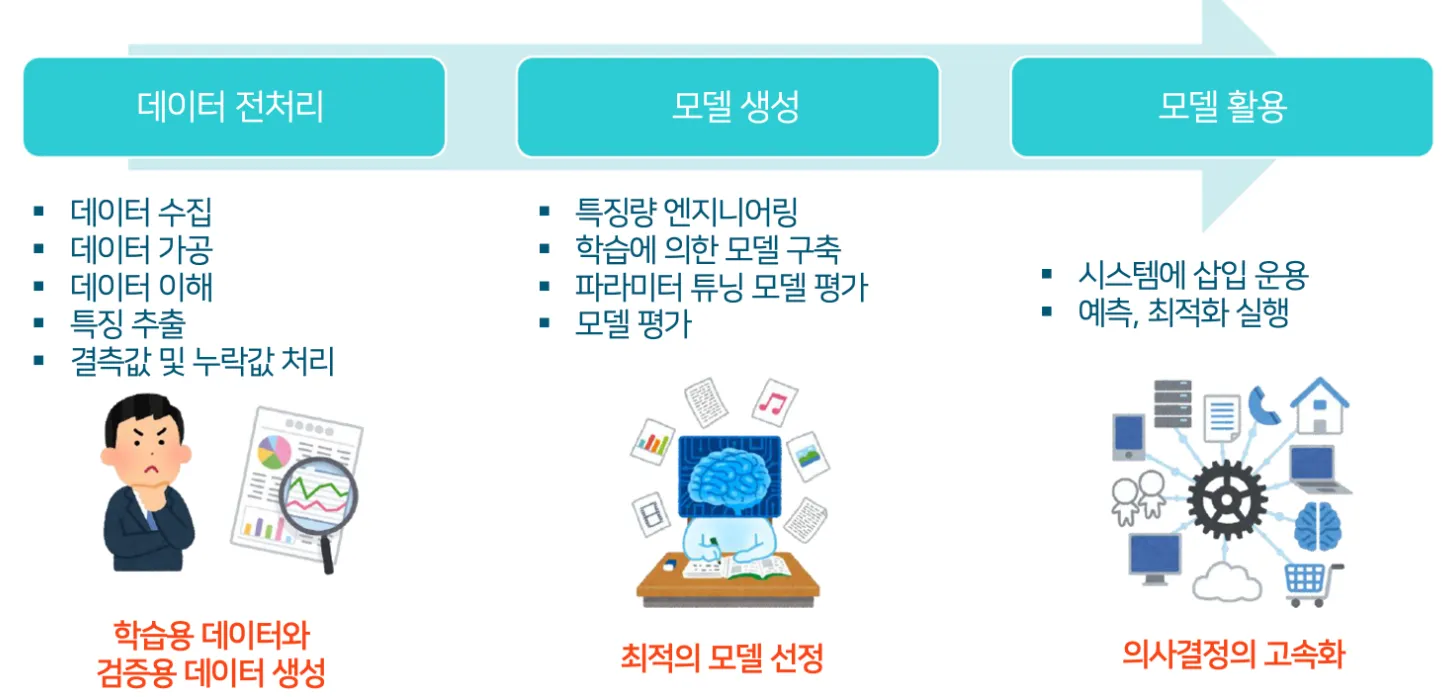
머신러닝 활용의 일반적인 흐름
•
데이터 전처리는 시간이 걸리고 손이 많이 가는 작업이지만 이 과정에서 정확하지 않은 데이터가 발생하면 분석 결과까지 영향을 미친다.
•
모델 생성은 특징량이나 알고리즘 선택, 모델 구축, 검증 등 전문성이 요구되는 공정이 많아 데이터 사이언티스트의 경험이나 역량에 의존하는 부분이 많다.
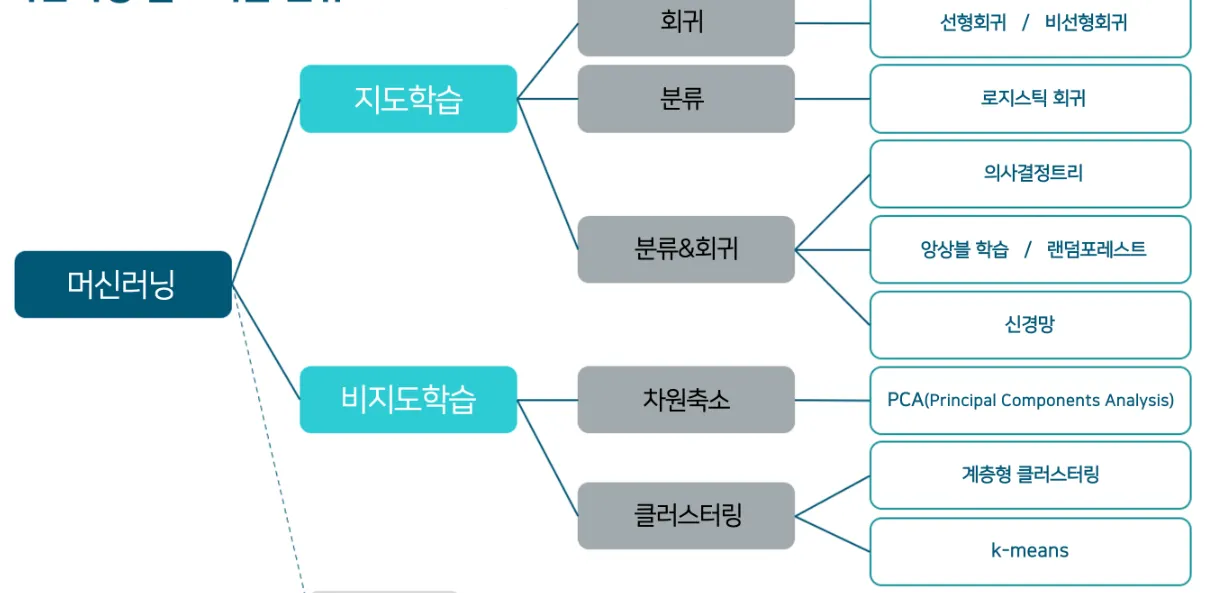
머신러닝 알고리즘
•
이렇게 수많은 머신러닝 알고리즘 중에서 내가 하려고 하는 분석에는 어떤 것이 최적인지 선택하는 것도 중요하다.
•
때문에 데이터를 활용하고 머신러닝 기술을 적용할 때는 데이터 사이언티스트의 역량이 많이 필요하다.
AutoML로 데이터 전처리 및 모델링 자동화
•
모든 조직에 데이터 사이언티스트를 배치하는 것은 현실적으로 어렵다.
•
이렇게 데이터 사이언티스트의 역량이 필요한 작업을 자동화하는 것이 바로 AutoML의 기능
•
무엇보다도 전문 인력이 부족한 조직에서 AutoML의 기능을 활용하면 효율적인 데이터 분석을 할 수 있다.

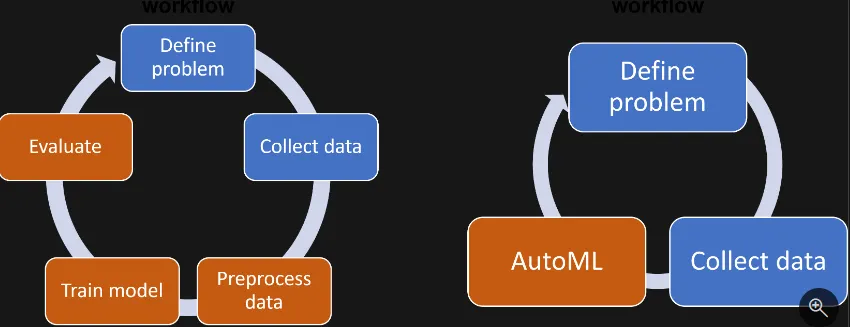
AutoML의 작동방식
•
일반적으로 기계 학습 모델을 학습시키는 워크플로는 다음과 같다.
◦
문제 정의
◦
데이터 수집
◦
데이터 전처리
◦
모델 학습
◦
모델 평가
AutoML은 언제 사용해야 하는가?
•
학습을 막 시작하고 있든, 경험이 풍부한 사용자이든 상관없이 AutoML은 모델 개발 프로세스를 자동화하기 위한 솔루션을 제공한다.
•
초보자
◦
기계 학습을 처음 사용하는 경우 AutoML은 모델을 학습시킬 때 결정해야 하는 결정 수를 줄이는 기본값 집합을 제공하여 모델 개발 프로세스를 간소화시킨다.
◦
이를 통해 데이터 및 해결하려는 문제에 초점을 맞출 수 있으며 AutoML에서 나머지 작업을 수행하도록 할 수 있다.
•
숙련된 사용자
◦
기계 학습에 대한 경험이 있는 경우 자동화 기능을 활용하면서 필요에 따라 AutoML에서 제공하는 기본값을 사용자 지정, 구성 및 확장할 수 있다.

•
PyCaret은 Machine Learning Workflow를 자동화하는 오픈소스 라이브러리
•
Classification, Regression, Clustering 등의 Task에서 사용하는 여러 모델들을 동일한 환경에서 한번에 한 줄의 코드로 실행할 수 있도록 자동화한 라이브러리
•
여러 모델을 비교할 수 있으며, 각 모델 별로 튜닝을 진행할 수도 있다.

설치
•
pip install pycaret[analysis] : 분석 관련 기능
•
pip install pycaret[models] : 모델 관련 기능
•
pip install pycaret[tuner] : 튜닝 관련 기능
•
pip install pycaret[mlops] : MLOps 관련 기능
•
pip install pycaret[parallel] : 병렬 처리 관련 기능
•
pip install pycaret[test] : 테스트 관련 기능
•
pip install pycaret[full] : 전체 버전
•
pip install pycaret : PyCaret의 기본 패키지
데이터 로드 - 예제 - pycaret tutorial
from pycaret.datasets import get_data
dataset = get_data('credit')
train = dataset.sample(frac=0.95, random_state=786)
test = dataset.drop(train.index)
train.reset_index(inplace=True, drop=True)
test.reset_index(inplace=True, drop=True)
Python
복사
데이터 설정
•
pycaret을 사용하기 전에 pycaret에 맞게 데이터를 설정해줘야 한다.
•
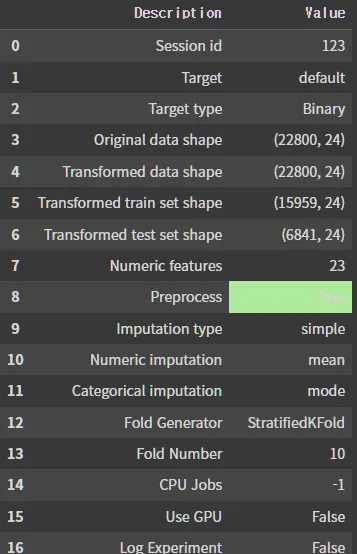
set_up() 함수를 사용하며, 기본적으로 data와 target을 입력해준다.
•
입력 후 column에 대한 자료형이 출력되며 enter를 치면 data가 설정된다.
•
set_up(): pycaret을 사용하기 위한 data setting
◦
session_id: random_state와 같은 개념으로 같은 결과가 나올 수 있게 seed를 고정
◦
data: train 데이터를 입력
◦
target: target 변수 이름을 입력
from pycaret.classification import *
exp_clf = setup(data = train, target = 'default', session_id=123)
Python
복사
모델 비교
•
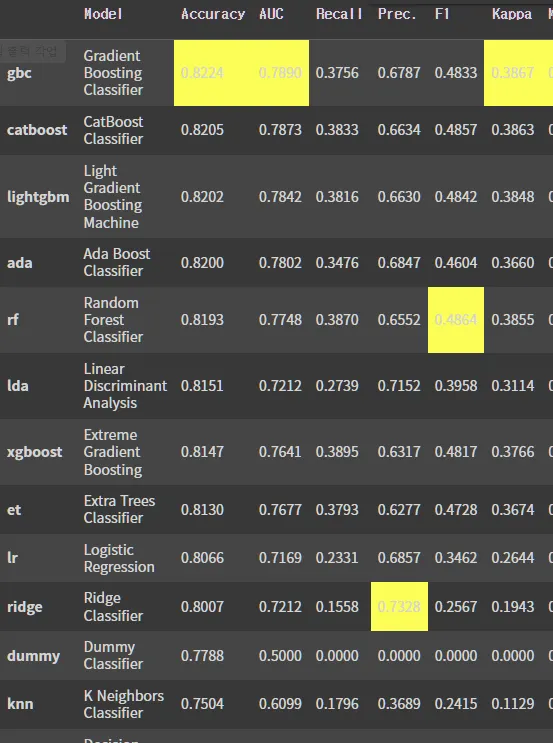
compare_models(): 다양한 모델 적합 후 성능 비교
◦
fold: cross_validation의 fold를 지정 (default = 10)
◦
sort: 정렬기준 지표 설정
◦
n_select: 상위 n개의 모델 결과만 출력
best_model = compare_models()
Python
복사
모델 분석
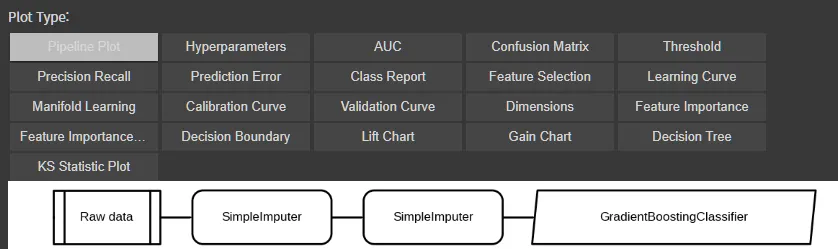
evaluate_model(best_model)
Python
복사
모델 예측
# predict on test set
> holdout_pred = predict_model(best_model)
Python
복사

# save pipeline
> save_model(best_model, 'my_first_pipeline')
Transformation Pipeline and Model Successfully Saved
(Pipeline(memory=Memory(location=None),
steps=[('numerical_imputer',
TransformerWrapper(exclude=None,
include=['LIMIT_BAL', 'SEX', 'EDUCATION',
'MARRIAGE', 'AGE', 'PAY_1',
'PAY_2', 'PAY_3', 'PAY_4', 'PAY_5',
'PAY_6', 'BILL_AMT1', 'BILL_AMT2',
'BILL_AMT3', 'BILL_AMT4',
'BILL_AMT5', 'BILL_AMT6',
'PAY_AMT1', 'PAY_AMT2', 'PAY_AMT3',
'PAY_AMT4', 'PAY_AMT5',
'PAY_AMT6'],
transform...
criterion='friedman_mse', init=None,
learning_rate=0.1, loss='log_loss',
max_depth=3, max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=100,
n_iter_no_change=None,
random_state=123, subsample=1.0,
tol=0.0001, validation_fraction=0.1,
verbose=0, warm_start=False))],
verbose=False),
'my_first_pipeline.pkl')
Python
복사
# load pipeline
loaded_best_pipeline = load_model('my_first_pipeline')
loaded_best_pipeline
Python
복사