



로드
구글 드라이브 연결
# 구글 드라이브 연결(데이터 로드를 위해서)
from google.colab import drive
drive.mount('/content/data')
Python
복사
라이브러리
# 데이터 분석에 사용할 라이브러리
import pandas as pd
import numpy as np
import logging
logging.getLogger('matplotlib.font_manager').setLevel(logging.ERROR)
# 데이터 시각화에 사용할 라이브러리
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
# 브라우저에서 바로 그려지도록
%matplotlib inline
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
# Colab 의 한글 폰트 설정
plt.rc('font', family='NanumBarunGothic')
# 유니코드에서 음수 부호설정
mpl.rc('axes', unicode_minus=False)
Python
복사
데이터 로드
타이타닉 데이터 로드
# PATH는 개인 Google drive PATH로 설정
DATA_PATH = "/content/data/MyDrive/Colab Notebooks/ai_study/1. Machine Learning/data/"
df = pd.read_csv(DATA_PATH+"Titanic.csv")
Python
복사
df.shape, df.columns
((891, 12),
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object'))
Python
복사
df.columns = [col.lower() for col in df.columns] # 컬럼명 소문자로 변환
df.columns
Index(['passengerid', 'survived', 'pclass', 'name', 'sex', 'age', 'sibsp',
'parch', 'ticket', 'fare', 'cabin', 'embarked'],
dtype='object')
Python
복사
데이터 분리
from sklearn.model_selection import train_test_split
SEED = 42
X_tr, X_te = train_test_split(df, random_state=SEED, test_size = 0.2)
X_tr = X_tr.reset_index(drop=True)
X_te = X_te.reset_index(drop=True)
X_tr.shape, X_te.shape
# ((712, 12), (179, 12))
Python
복사
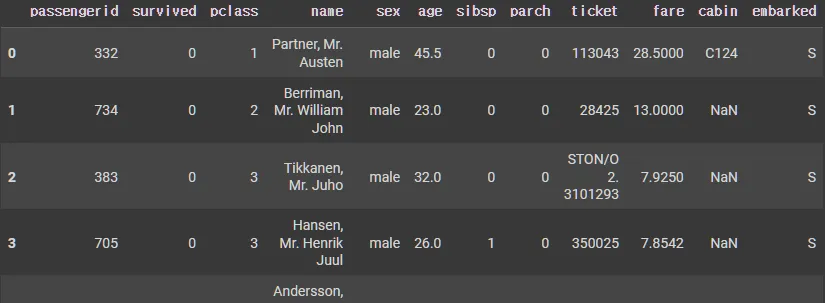
X_tr.head()
Python
복사
X_tr.columns
Index(['passengerid', 'survived', 'pclass', 'name', 'sex', 'age', 'sibsp',
'parch', 'ticket', 'fare', 'cabin', 'embarked'],
dtype='object')
Python
복사
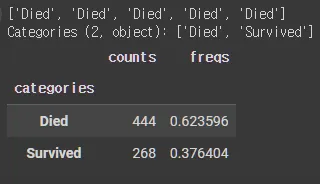
new_survived = pd.Categorical(X_tr['survived'])
new_survived = new_survived.rename_categories(["Died","Survived"])
print(new_survived[:5])
new_survived.describe()
Python
복사
데이터 확인
X_tr.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 passengerid 712 non-null int64
1 survived 712 non-null int64
2 pclass 712 non-null int64
3 name 712 non-null object
4 sex 712 non-null object
5 age 572 non-null float64
6 sibsp 712 non-null int64
7 parch 712 non-null int64
8 ticket 712 non-null object
9 fare 712 non-null float64
10 cabin 159 non-null object
11 embarked 710 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 66.9+ KB
Python
복사
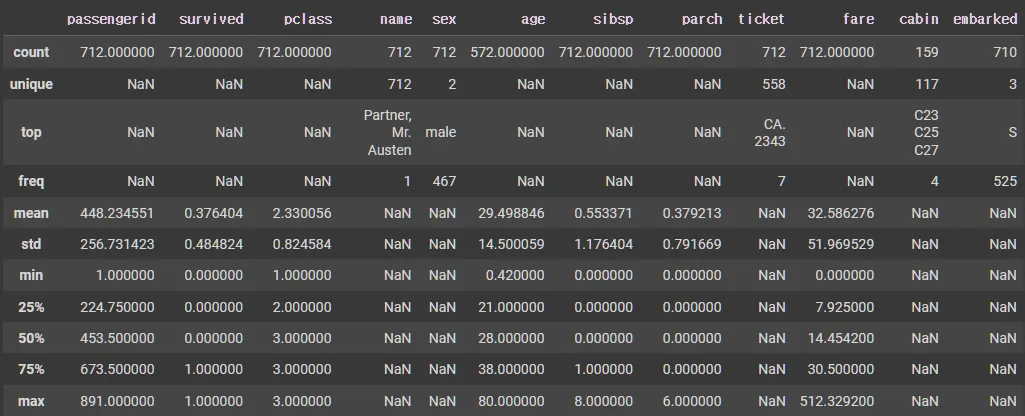
X_tr.describe(include="all")
Python
복사
X_tr.describe(include=np.number)
Python
복사
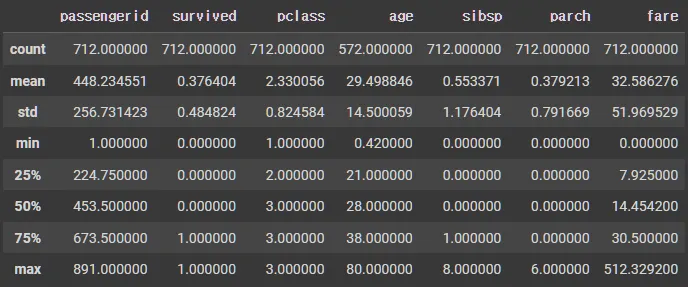
X_tr.describe(exclude=np.number)
Python
복사
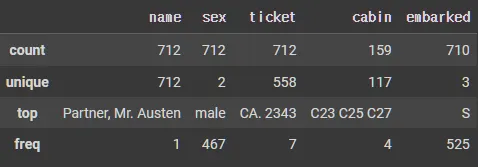
X_tr.head()
X_tr.tail()
Python
복사


타겟 데이터 확인
new_survived = pd.Categorical(X_tr["survived"])
new_survived = new_survived.rename_categories(["Died","Survived"])
new_survived.describe()
Python
복사
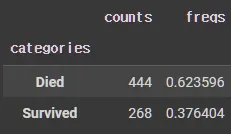
Data Cleaning
필요없는 데이터 (unique한 데이터 삭제)
X_tr['passengerid'].nunique(), X_tr.shape[0]
# (712, 712)
Python
복사
# passengerid는 전체 데이터가 unique하기 때문에 삭제
X_tr.drop('passengerid', axis=1, inplace=True)
X_te.drop('passengerid', axis=1, inplace=True)
X_tr.columns
Index(['survived', 'pclass', 'name', 'sex', 'age', 'sibsp', 'parch', 'ticket',
'fare', 'cabin', 'embarked'],
dtype='object')
Python
복사
결측치 처리
# 각 걸럼별 결측치 비율
(X_tr.isnull().sum() / X_tr.shape[0]).round(4).sort_values(ascending=False)
# X_tr.isnull().sum(): X_tr 데이터프레임의 각 열에서 결측치의 총 개수를 계산
# isnull(): 데이터프레임의 각 요소가 결측치인지 아닌지를 Boolean 값으로 반환
# sum(): 각 열에서 True의 개수를 세어 결측치의 총 개수를 계산
# X_tr.shape[0]: X_tr 데이터프레임의 총 행 수를 반환
# shape 속성의 첫 번째 값(shape[0])은 데이터프레임의 행 수를 나타냅니다. 결측치 비율을 계산하기 위해 전체 데이터의 개수를 사용
# (X_tr.isnull().sum() / X_tr.shape[0]): 각 열의 결측치 비율을 계산
# 각 열의 결측치 개수를 전체 행 수로 나누어 비율을 구함
# 예를 들어, 특정 열에서 결측치가 10개이고 전체 행이 100개라면,
# 비율은 10 / 100 = 0.1 즉, 10%
# .round(4): 계산된 결측치 비율을 소수점 4자리까지 반올림
# round(4): 결측치 비율을 소수점 4자리까지 반올림하여 결과를 더 읽기 쉽게 만듬
# .sort_values(ascending=False)
# 결측치 비율을 내림차순으로 정렬
# sort_values(ascending=False): 비율이 높은 순서대로 열을 정렬
# 결측치가 많은 열이 먼저 나오게 되어, 데이터 클리닝에서 우선적으로 처리해야 할 열을 쉽게 파악 가능
Python
복사
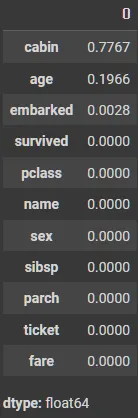
print(f'before: {X_tr.shape} / isnull().sum(): {X_tr.isnull().sum().sum()}')
# 결측치가 있는 행 제거 : X_tr.dropna(axis=0)
X_tr = X_tr.drop('cabin', axis=1)
X_te = X_te.drop('cabin', axis=1)
print(f'after: {X_tr.shape} / isnull().sum(): {X_tr.isnull().sum().sum()}')
# before: (712, 11) / isnull().sum(): 695
# after: (712, 10) / isnull().sum(): 142
Python
복사
X_tr['age'] = X_tr['age'].fillna(X_tr['age'].median())
X_te['age'] = X_te['age'].fillna(X_tr['age'].median())
Python
복사
embarked_mode = X_tr['embarked'].mode().values[0]
X_tr['embarked'] = X_tr['embarked'].fillna(embarked_mode)
X_te['embarked'] = X_te['embarked'].fillna(embarked_mode)
Python
복사
X_tr.isnull().sum().sum(), X_te.isnull().sum().sum()
# (553, 134)
Python
복사
Feature Extraction
•
기존 Feature에 기반하여 새로운 Feature들을 생성
•
데이터 타입
X_tr.info()
Python
복사
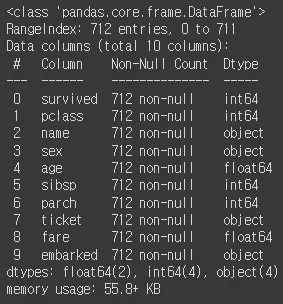
수치형 데이터 타입 변환
df_number = X_tr.select_dtypes(include=np.number)
df_number.columns
# Index(['survived', 'pclass', 'age', 'sibsp', 'parch', 'fare'], dtype='object')
df_number.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 712 non-null int64
1 pclass 712 non-null int64
2 age 712 non-null float64
3 sibsp 712 non-null int64
4 parch 712 non-null int64
5 fare 712 non-null float64
dtypes: float64(2), int64(4)
memory usage: 33.5 KB
df_number.head()
Python
복사
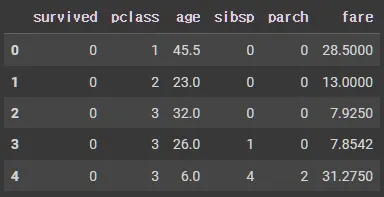
# survived
X_tr["survived"] = X_tr["survived"].astype("int32")
X_te["survived"] = X_te["survived"].astype("int32")
# pclass
X_tr['pclass'].unique()
# array([1, 2, 3])
Python
복사
X_tr["pclass"] = X_tr["pclass"].astype("category")
X_te["pclass"] = X_te["pclass"].astype("category")
# age
X_tr["age"] = X_tr["age"].astype("int32")
X_te["age"] = X_te["age"].astype("int32")
# sibsp
X_tr['sibsp'].unique()
# array([0, 1, 4, 3, 2, 8, 5])
Python
복사
X_tr["sibsp"] = X_tr["sibsp"].astype("category")
X_te["sibsp"] = X_te["sibsp"].astype("category")
# parch
X_tr['parch'].unique()
# array([0, 2, 1, 6, 4, 3, 5])
Python
복사
X_tr["parch"] = X_tr["parch"].astype("category")
X_te["parch"] = X_te["parch"].astype("category")
# fare
X_tr["fare"] = X_tr["fare"].astype("float32")
X_te["fare"] = X_te["fare"].astype("float32")
X_tr.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 712 non-null int32
1 pclass 712 non-null category
2 name 712 non-null object
3 sex 712 non-null object
4 age 712 non-null int32
5 sibsp 712 non-null category
6 parch 712 non-null category
7 ticket 712 non-null object
8 fare 712 non-null float32
9 embarked 712 non-null object
dtypes: category(3), float32(1), int32(2), object(4)
memory usage: 33.6+ KB
Python
복사
범주형 데이터 타입 변환
df_object = X_tr.select_dtypes(include='object')
df_object.columns
# Index(['name', 'sex', 'ticket', 'embarked'], dtype='object')
df_object.head()
Python
복사
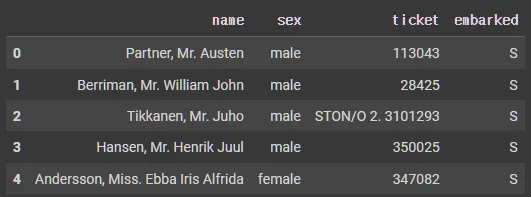
X_tr["sex"] = X_tr["sex"].astype("category")
X_te["sex"] = X_te["sex"].astype("category")
X_tr["embarked"] = X_tr["embarked"].astype("category")
X_te["embarked"] = X_te["embarked"].astype("category")
X_tr.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 712 non-null int32
1 pclass 712 non-null category
2 name 712 non-null object
3 sex 712 non-null category
4 age 712 non-null int32
5 sibsp 712 non-null category
6 parch 712 non-null category
7 ticket 712 non-null object
8 fare 712 non-null float32
9 embarked 712 non-null category
dtypes: category(5), float32(1), int32(2), object(2)
memory usage: 24.1+ KB
# ---------------------------------------------------------------------
X_tr.head()
Python
복사
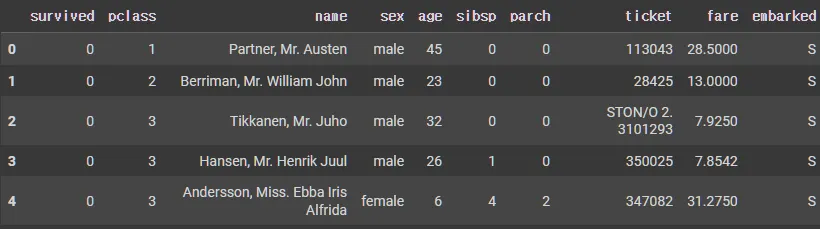
문자열
df_object = X_tr.select_dtypes(include='object')
df_object.columns
# Index(['name', 'sex', 'ticket', 'cabin', 'embarked'], dtype='object')
df_object.head()
Python
복사
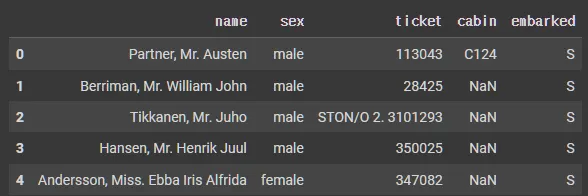
df_object.describe()
Python
복사
공백제거
•
앞뒤 공백제거, lstrip , rstrip
X_tr["name"] = X_tr["name"].map(lambda x: x.strip())
X_tr["ticket"] = X_tr["ticket"].map(lambda x: x.strip())
X_te["name"] = X_te["name"].map(lambda x: x.strip())
X_te["ticket"] = X_te["ticket"].map(lambda x: x.strip())
df_object.head()
Python
복사
문자열 포함 여부
dict_designation = {
'Mr.': '남성',
'Master.': '남성',
'Sir.': '남성',
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',
'Lady.': '숙녀',
'Mlle.': '아가씨',
# 직업
'Dr.': '의사',
'Rev.': '목사',
'Major.': '계급',
'Don.': '교수',
'Col.': '군인',
'Capt.': '군인',
# 귀족
'Mme.': '영부인',
'Countess.': '백작부인',
'Jonkheer.': '귀족'
}
dict_designation.keys()
# dict_keys(['Mr.', 'Master.', 'Sir.', 'Miss.', 'Mrs.', 'Ms.', 'Lady.', 'Mlle.', 'Dr.', 'Rev.', 'Major.', 'Don.', 'Col.', 'Capt.', 'Mme.', 'Countess.', 'Jonkheer.'])
# X_tr['name'].map(lambda x: x) ->
x = 'Andersson, Miss. Ebba Iris Alfrida '
x
# Andersson, Miss. Ebba Iris Alfrida\t
'Mr.' in x
# False
'Miss.' in x
# True
Python
복사
for key in dict_designation.keys():
result = 'unknown'
if key in x:
result = key
break
print(result)
# Miss.
Python
복사
dict_designation = {
'Mr.': '남성',
'Master.': '남성',
'Sir.': '남성',
'Miss.': '미혼 여성',
'Mrs.': '기혼 여성',
'Ms.': '미혼/기혼 여성',
'Lady.': '숙녀',
'Mlle.': '아가씨',
# 직업
'Dr.': '의사',
'Rev.': '목사',
'Major.': '계급',
'Don.': '교수',
'Col.': '군인',
'Capt.': '군인',
# 귀족
'Mme.': '영부인',
'Countess.': '백작부인',
'Jonkheer.': '귀족'
}
def add_designation(name): # 호칭 함수
designation = "unknown"
for key in dict_designation.keys():
if key in name:
designation = key
break
return designation
X_tr['designation'] = X_tr['name'].map(lambda x: add_designation(x))
X_te['designation'] = X_te['name'].map(lambda x: add_designation(x))
X_tr.head()
Python
복사
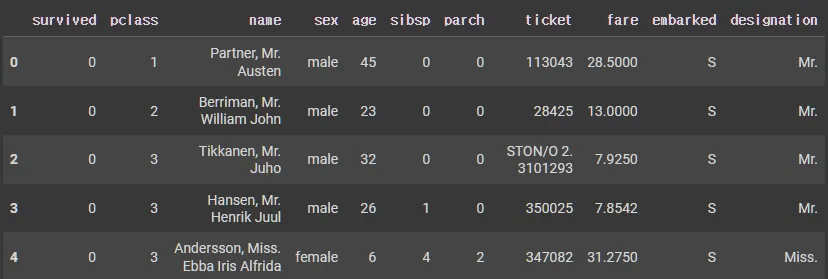
cond = X_tr['designation'] == "unknown"
X_tr.loc[cond].head()
Python
복사

X_tr[X_tr['designation'] == "unknown"].shape
# (0, 11)
cond = X_te['designation'] == "unknown"
X_te.loc[cond].head()
Python
복사

문자열 분리
X_tr['name'].head()
Python
복사

# 1. Mr. 이런거 삭제... -> replace()
# 2. , 이걸로 나누기.... -> split()
# 3. 라스트 네임 추출
# 4. 새로운 컬럼에 적용
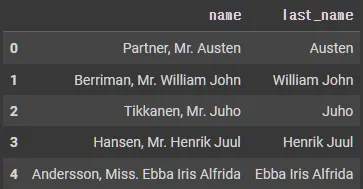
def get_last_name(name):
last_name = None
try:
for key in dict_designation.keys(): # 이니셜을 다 조회하기
if key in name: # 이니셜이 있는지 확인하기
name = name.replace(key,'') # 이니셜을 제거하기
last_name = name.split(',')[1].strip() # 라스트 네임 추출하기
except:
pass
return last_name
X_tr['last_name'] = X_tr['name'].map(lambda x: get_last_name(x))
X_te['last_name'] = X_te['name'].map(lambda x: get_last_name(x))
X_tr[['name', 'last_name']].head()
Python
복사
# X_tr['last_name'] = X_tr['name'].map(lambda x: x.split(',')[1].split('.')[1])
# X_te['last_name'] = X_te['name'].map(lambda x: x.split(',')[1].split('.')[1])
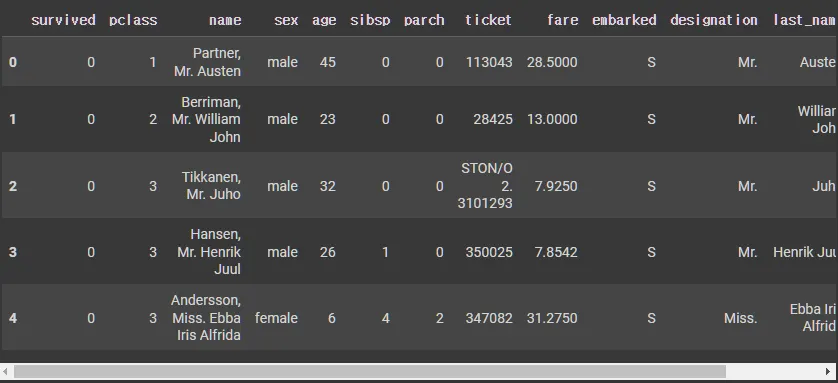
X_tr['first_name'] = X_tr['name'].map(lambda x: x.split(',')[0].strip())
X_te['first_name'] = X_te['name'].map(lambda x: x.split(',')[0].strip())
X_tr.head()
# X_tr.tail()
Python
복사
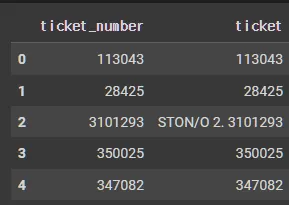
X_tr['ticket']
Python
복사
def add_ticket_number(ticket):
try:
ticket_split = ticket.split(' ')
return int(ticket_split[-1])
except:
return 0 # ticket이 LINE인 경우
X_tr['ticket_number'] = X_tr['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
X_te['ticket_number'] = X_te['ticket'].map(lambda x: add_ticket_number(x)).astype("int32")
X_tr[['ticket_number', 'ticket']].head()
Python
복사
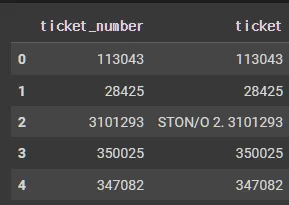
X_tr[['ticket_number', 'ticket']].info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 712 entries, 0 to 711
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ticket_number 712 non-null int32
1 ticket 712 non-null object
dtypes: int32(1), object(1)
memory usage: 8.5+ KB
Python
복사
집계
피봇 테이블
X_tr.head()
Python
복사
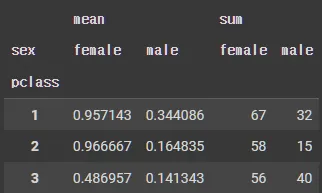
df_pivot = pd.pivot_table(X_tr, # 피벗할 데이터프레임
index='pclass', # 행 위치에 들어갈 열
column='', # 열 위치에 들어갈 열
values='fare', # 데이터로 사용할 열
aggfunc='mean').reset_index() # 데이터 집계함 수
df_pivot.rename(columns = {'fare' : 'fare_mean_by_pclass'}, inplace = True)
df_pivot #.head()
Python
복사
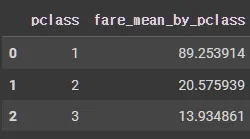
pivot = pd.pivot_table(X_tr, # 피벗할 데이터프레임
index = 'pclass', # 행 위치에 들어갈 열
columns = 'sex', # 열 위치에 들어갈 열
values = 'survived', # 데이터로 사용할 열
aggfunc = ['mean', 'sum']) # 데이터 집계함수
pivot
Python
복사
print(f'before: {X_tr.shape}')
X_tr = pd.merge(X_tr,df_pivot,how="left",on="pclass")
X_te = pd.merge(X_te,df_pivot,how="left",on="pclass")
print(f'after: {X_tr.shape}')
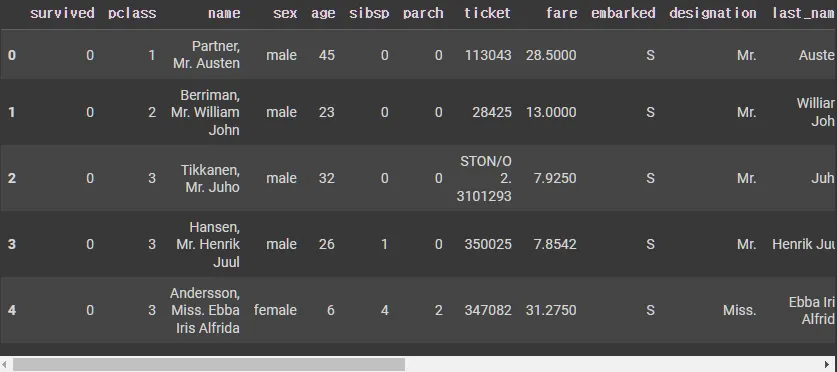
X_tr.head()
Python
복사
그룹
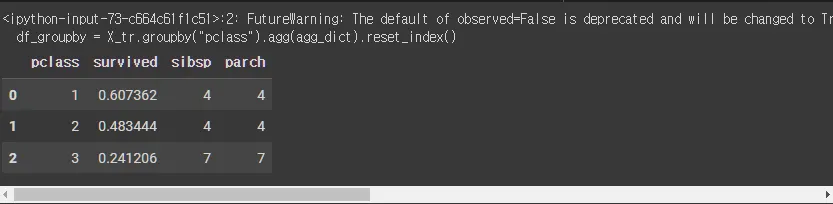
agg_dict = {"survived" : "mean" , "sibsp" : "nunique", "parch" : "nunique" }
df_groupby = X_tr.groupby("pclass").agg(agg_dict).reset_index()
df_groupby
Python
복사
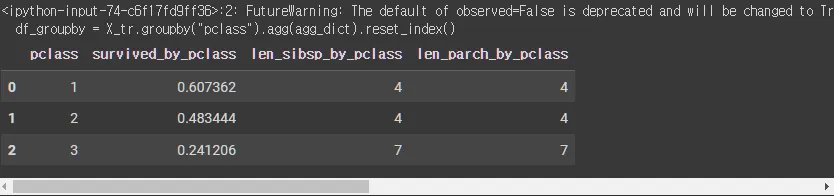
agg_dict = {"survived" : "mean" , "sibsp" : "nunique", "parch" : "nunique" }
df_groupby = X_tr.groupby("pclass").agg(agg_dict).reset_index()
df_groupby.rename(columns = {'survived' : 'survived_by_pclass', 'sibsp' : 'len_sibsp_by_pclass', 'parch' : 'len_parch_by_pclass'}, inplace = True)
df_groupby
Python
복사
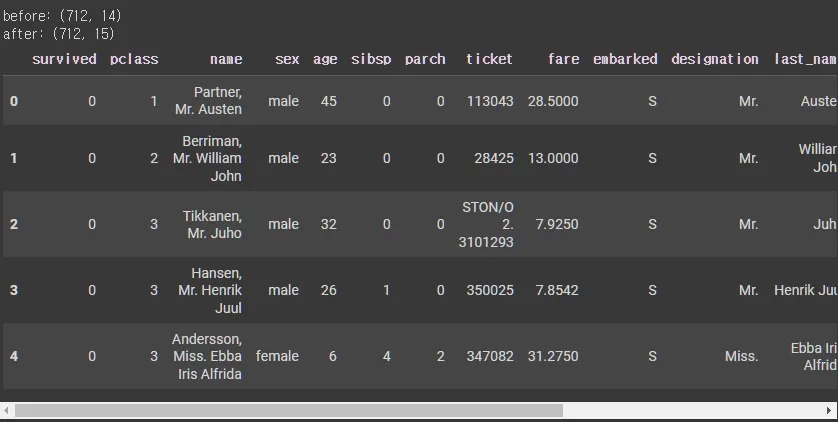
print(f'before: {X_tr.shape}')
X_tr = pd.merge(X_tr,df_groupby,how="left",on="pclass")
X_te = pd.merge(X_te,df_groupby,how="left",on="pclass")
print(f'after: {X_tr.shape}')
X_tr.head()
# before: (712, 15)
# after: (712, 18)
Python
복사
데이터 변환/조합
•
apply(), map() 등 사용
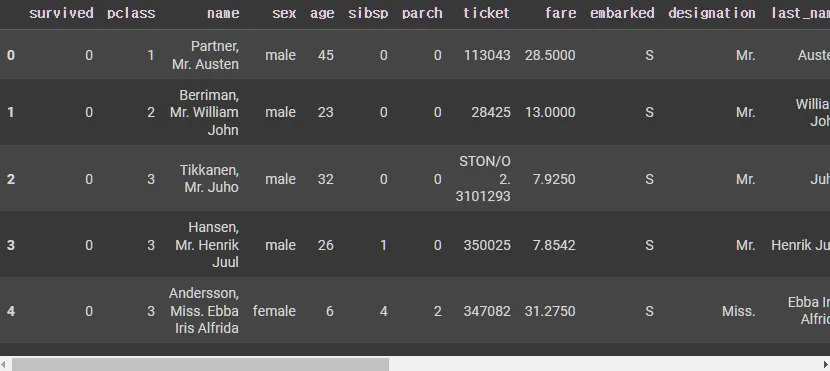
def sub_age(age):
return age // 10
X_tr['sub_age'] = X_tr['age'].map(lambda x: sub_age(x))
X_te['sub_age'] = X_te['age'].map(lambda x: sub_age(x))
X_tr.head()
Python
복사
•
범주형 데이터들은 무지성 조합해서 넣을 경우 학습 정확도가 올라감
수치형은 정확도가 떨어짐
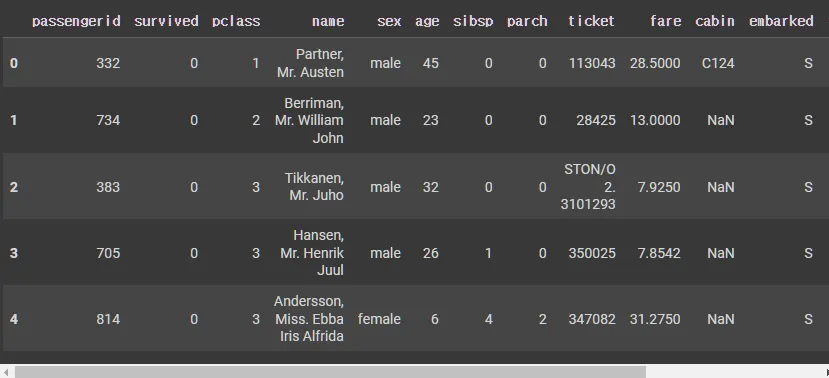
def add_sub_embarked(row):
return str(row['embarked']) + str(row['pclass']) + str(row['sibsp']) + str(row['parch'])
X_tr['sub_embarked'] = X_tr.apply(lambda row: add_sub_embarked(row), axis=1)
X_te['sub_embarked'] = X_te.apply(lambda row: add_sub_embarked(row), axis=1)
X_tr.head()
Python
복사
날짜 (시계열)
•
드라이브에서 시네마 데이터 불러오기
DATA_PATH = "/content/drive/MyDrive/Colab Notebooks/ai_study/1. Machine Learning/data/"
df_cinemaTicket = pd.read_csv(DATA_PATH+"cinemaTicket_Ref.csv")
df_cinemaTicket.shape
# (142524, 14)
Python
복사
•
점보
df_cinemaTicket.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 142524 entries, 0 to 142523
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 film_code 142524 non-null int64
1 cinema_code 142524 non-null int64
2 total_sales 142524 non-null int64
3 tickets_sold 142524 non-null int64
4 tickets_out 142524 non-null int64
5 show_time 142524 non-null int64
6 occu_perc 142399 non-null float64
7 ticket_price 142524 non-null float64
8 ticket_use 142524 non-null int64
9 capacity 142399 non-null float64
10 date 142524 non-null object
11 month 142524 non-null int64
12 quarter 142524 non-null int64
13 day 142524 non-null int64
dtypes: float64(3), int64(10), object(1)
memory usage: 15.2+ MB
Python
복사
datetime 적용
•
데이터 타입 변환
df_cinemaTicket["date"] = pd.to_datetime(df_cinemaTicket["date"])
df_cinemaTicket.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 142524 entries, 0 to 142523
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 film_code 142524 non-null int64
1 cinema_code 142524 non-null int64
2 total_sales 142524 non-null int64
3 tickets_sold 142524 non-null int64
4 tickets_out 142524 non-null int64
5 show_time 142524 non-null int64
6 occu_perc 142399 non-null float64
7 ticket_price 142524 non-null float64
8 ticket_use 142524 non-null int64
9 capacity 142399 non-null float64
10 date 142524 non-null datetime64[ns]
11 month 142524 non-null int64
12 quarter 142524 non-null int64
13 day 142524 non-null int64
dtypes: datetime64[ns](1), float64(3), int64(10)
memory usage: 15.2 MB
Python
복사
•
뽑을 수 있는 데이터
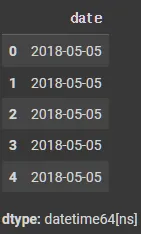
df_cinemaTicket["date"][:5]
Python
복사
◦
연도
df_cinemaTicket["date"].dt.year[:5] # 연도
Python
복사
◦
월
df_cinemaTicket["date"].dt.month[:5] # 월
Python
복사
◦
일
df_cinemaTicket["date"].dt.day[:5] # 일
Python
복사
◦
분기
df_cinemaTicket["date"].dt.quarter[:5] # 분기
Python
복사
◦
요일 : 0 ~ 6 (월~일)
df_cinemaTicket["date"].dt.weekday[:5] # 요일: 0 ~ 6(월요일 ~ 일요일)
Python
복사
◦
연기준 몇일째인지
df_cinemaTicket["date"].dt.dayofyear[:5] # 연기준 몇일째인지..
Python
복사
진행자(tqdm)
•
파이썬에서 반복 루프를 돌다 보면 진행이 얼마나 되었는지 Progress Bar를 통해 알 수 있다.
•
이처럼 반복문에서 진행률을 Progress Bar로 표현해주고 남은 시간 정보까지 알려주는 것이 바로 tqdm
설치
!pip install tqdm
from tqdm.auto import tqdm
# 예제
i=0
for i in tqdm(np.random.rand(10000000)):
i = i**2
Python
복사
tqdm 파라미터
•
iterable: 반복자 객체
•
desc: 진행바 앞에 텍스트 출력
•
total: int, 전체 반복량
•
leave: bool, default로 True (진행상태 잔상이 남음)
•
ncols: 진행바 컬럼길이
◦
width값으로 pixel 단위로 보임
•
mininterval, maxinterval: 업데이트 주기
◦
기본은 mininterval=0.1 sec, maxinterval=10 sec
•
miniters: Minimum progress display update interval, in iterations.
•
ascii: True로 하면 #문자로 진행바가 표시됨
•
initial: 진행 시작값. 기본은 0
•
colour: 'blue', '#0000ff' (헥스코드로도 입력 가능)
•
position: 바 위치 설정. 여러개의 바 관리할 때 지정
import time
iterable = ['a','b','c']
for i in tqdm(
iterable, # 반복가능한 iterable 객체
desc = 'Description', # 프로그레스 바 맨 앞에 나타날 문구
colour = 'blue', # '#0000ff' 헥스코드로도 입력 가능
position = 0 # 바 위치 설정. 여러개의 바 관리할 때 지정
):
time.sleep(0.1)
Python
복사

Manual
•
with 구문을 사용해서 tqdm을 수동으로 컨트롤한다.
•
update()로 수동으로 진행률을 증가 시킨다.
iterable = ['a', 'b', 'c', 'd', 'e']
with tqdm(iterable,
total = len(iterable), ## 전체 진행수
desc = 'Description', ## 진행률 앞쪽 출력 문장
ascii = ' =', ## 바 모양, 첫 번째 문자는 공백이어야 작동
leave = True, ## True 반복문 완료시 진행률 출력 남김. False 남기지 않음.
) as pbar:
for c in pbar:
pbar.set_description(f'Current Character "{c}"') ## 또는 pbar.desc = f'Current Character "{c}"'
time.sleep(0.2)
Python
복사

iterable = ['a', 'b', 'c', 'd', 'e']
pbar = tqdm(iterable,
total = len(iterable), ## 전체 진행수
desc = 'Description', ## 진행률 앞쪽 출력 문장
ascii = ' =', ## 바 모양, 첫 번째 문자는 공백이어야 작동
leave = True, ## True 반복문 완료시 진행률 출력 남김. False 남기지 않음.
)
for c in pbar:
pbar.set_description(f'Current Character "{c}"') ## 또는 pbar.desc = f'Current Character "{c}"'
time.sleep(0.2)
pbar.close() # with를 사용하지 않은 경우에는 꼭 close()를 해야함!
Python
복사

★★ 이중 루프(Nested Loop)
•
두 개 이상 for문이 있는 경우
import time
for outer in tqdm([10, 20, 30, 40, 50], desc='outer', position=0): ## 출력되는 라인을 나타내는 position을 0 으로 두고
for inner in tqdm(range(outer), desc='inner', position=1, leave=False): ## 안쪽 루프의 진행률 출력은 그 아랫줄인 position = 1 로 설정하는 것이다.
time.sleep(0.1)
Python
복사

•
주피터 노트북

pandas
tqdm.pandas() # 판다스에서 progress_apply 메소드를 사용할수 있게 된다.
import time
def do_apply(x):
time.sleep(0.01)
return x
tmp = df.progress_apply(do_apply,axis = 1)
Python
복사

