


자주 사용되는 표준 라이브러리
itertools : 순열, 조합
•
파이썬에서 반복되는 형태의 데이터(순열, 조합)를 처리하기 위한 유용한 기능들 제공
◦
순열 : 서로 다른 n개에서 서로 다른 r개를 선택하여 일렬로 나열하는 것
▪
n P r
◦
조합 : 서로 다른 n개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
▪
n C r
heapq 힙
•
힙(heap) 자료 구조 제공
◦
일반적으로 우선순위 큐 기능을 구현하기 위해 사용됨
bisect : 이진 탐색 트리
•
이진 탐색 기능 제공
◦
이진 탐색 : 정렬돼 있는 데이터에서 특정한 값을 찾아내는 알고리즘
collections : 큐, iterable 원소
•
덱(deque), 카운터(counter) 등의 유용한 자료구조 포함
math
•
팩토리얼, 제곱근, 최대공약수, 삼각함수, 파이 등
◦
math.ceil() : 실수 올림
◦
math.floor() : 실수 내림
자주 사용되는 내장함수 & 알고리즘
eval() : 사칙연산
•
기본 수학 계산
math = eval("3 + 4 * 7")
print(math)
Python
복사
sort() : 정렬
•
key값으로 정렬
l = [['홍길동', 35], ['이순신', 75], ['아무개', 50]]
print(l)
l.sort(key = lambda x: x[1], reverse = True)
print(l)
Python
복사
•
2차원 배열 동시 정렬
l = [['홍길동', 35], ['이순신', 75], ['아무개', 80]]
print(l)
l.sort(key = lambda x: (x[0], x[1])) # 0번쨰 -> 1번째
print(l)
Python
복사
진수 변환 : bin, oct, hex
•
bin() : 2진수
•
oct() : 8진수
•
hex() : 16진수
→ 10진수 : int를 받아, 해당하는 진수를 str로 반환
•
모든 진수 변환
def converter(num, b):
# 자연수(num)를 b진수로 변환
tmp = '' # 초기화
while num:
tmp += str(num % b) # 나머지를 스택에 저장
num = num // b # 몪은 다시 num으로 반환
return tmp[::-1] # 역순 반환
Python
복사
•
n진수를 10진수로 변환
int(tmp[::-1], 2) # 2진수를 10진수로
Python
복사
숫자 판별/예외처리함수
1.
int(number) or float(number)
number = input('Enter a number:')
try:
number = float(number)
except:
print('Invalid input')
# or
try:
number = int(input('Enter a number:'))
except:
print('Invalid input')
Python
복사
2.
number.isnumeric() : 정수확인
•
number이 숫자값이니? 라고 묻는 것
•
숫자값 표현에 해당하는 문자열까지 True로 반환
(제곱근, 분수, 거듭제곱 형태의 특수문자 → True)
(음수값, %, float 형태 → Flase)
number = input('Enter a number:')
if not(number.isnumeric()):
print('Invalid input')
number = ['123', '-1', '0.5', '½', '3²', '50%']
for i in number:
print(i, i.isnumeric())
> 123 True
-1 False
0.5 False
½ True
3² True
50% False
Python
복사
3.
number.isdigit()
•
해당 문자열이 '숫자'로 이루어져 있는지 검사
•
‘숫자처럼 생긴’ 모든 글자를 다 숫자로 치는 것
number = ['123', '-1', '0.5', '½', '3²', '50%']
for i in number:
print(i, i.isdigit())
> 123 True
-1 False
0.5 False
½ False
3² True
50% False
Python
복사
4.
number.isdecimal()
•
흔히 생각하는 ‘숫자’와 같은 개념. int로 반환되는 문자를 검사
•
따라서 int로 변환가능한지 보려면 isdecimal()를 사용
number = ['123', '-1', '0.5', '½', '3²', '50%']
for i in number:
print(i, i.isdecimal())
> 123 True
-1 False
0.5 False
½ False
3² False
50% False
Python
복사
소수 구하기
•
에라토스테네스의 체 (개수 구하기, 종류 보기)
# 소수 개수 구하기
def solution(n):
answer = 0
t_f = [False, False] + [True for _ in range(2, n + 1)]
for i in range(2, n + 1):
if t_f[i]:
answer +=1
for j in range(i * i, n + 1, i):
t_f[j] = False
return answer
# 소수 종류 보기
def solution2(n):
a = [False,False] + [True]*(n-1)
primes=[]
for i in range(2,n+1):
if a[i]:
primes.append(i)
for j in range(2*i, n+1, i):
a[j] = False
return primes
Python
복사
•
소수 판별(제곱근)
import math
# 2이상의 자연수에 대해
def is_prime(n):
# 2부터 (x - 1)까지의 모든 수를 확인하며
for i in range(2, int(math.sqrt(n))+1): # 제곱근까지만 확인
# x가 해당 수로 나누어떨어진다면
if n % i == 0:
return False # 소수X
return True # 소수
Python
복사
itertools
•
순열, 조합
# 순열
from itertools import permutations
data = ['a', 'b', 'c']
result = list(permutations(data, 2)) # 3개
print(result) # [('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'c'), ('c', 'a'), ('c', 'b')]
Python
복사
# 조합
from itertools import combinations
data = ['a', 'b', 'c']
result = list(combinations(data, 2)) # 2개
print(result) # [('a', 'b'), ('a', 'c'), ('b', 'c')]
Python
복사
•
중복 순열과 중복 조합
# 순열 1
from itertools import product
data = ['a', 'b', 'c']
result = list(product(data, repeat = 2))
print(result)
# [('a', 'a'), ('a', 'b'), ('a', 'c'), ('b', 'a'), ('b', 'b'), ('b', 'c'), ('c', 'a'), ('c', 'b'), ('c', 'c')]
# 순열 2
from itertools import product
l = ['ab', '12']
s = list(product(*l))
print(s)
# [('a', '1'), ('a', '2'), ('b', '1'), ('b', '2')]
Python
복사
#combinations_with_replacement
from itertools import combinations_with_replacement
data = ['a', 'b', 'c']
result = list(combinations_with_replacement(data, 2))
print(result)
Python
복사
collections.Counter
•
반복 가능한(iterable) 객체가 주어졌을 때 내부 원소 등장 횟수 반환
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(counter['red']) # 'red'가 등장한 횟수
# 2
print(dict(counter)) # 사전 형태로 반환
# {'red': 2, 'blue': 3, 'green': 1}
Python
복사
최대 공약수와 최소 공배수
•
math 라이브러리의 gcd(): 최대 공약수 계산
import math
# 최소 공배수 구하는 함수
def lcm(a, b):
return a * b # math.gcd(a,b)
print(lcm(21, 14))
# 최대 공약수 구하는 함수
print(math.gcd(21, 14))
Python
복사
•
유클리드 호제법
◦
두 자연수 A, B에 관해 (A>B) A를 B로 나눈 나머지를 R이라 한다.
▪
이때 A와 B의 최대공약수는 B와 R의 최대공약수와 같다.
# gcd 제작
def gcd(a,b):
if a % b == 0:
return b
else :
return gcd(b, a%b)
print(gcd(192,162))
Python
복사
Deque(덱)
•
Deque(덱)는 double-ended-queue의 줄임말로, 양방향에서 데이터를 처리할 수 있는 queue형 자료구조
•
양방향에서 엘리먼트를 추가, 삭제할 수 있는 양방향 큐

•
메서드
◦
deque.append(x) : x를 데크의 오른쪽 끝에 삽입
◦
deque.appendleft(x) : x를 데크의 왼쪽 끝에 삽입
◦
deque.pop() : 데크의 오른쪽 끝(마지막) 엘리먼트를 가져오는 동시에 데크에서는 삭제
◦
deque.popleft() : 데크의 왼쪽 끝(처음) 엘리먼트를 가져오는 동시에 데크에서는 삭제
◦
deque.extend(array) : 배열 array를 순환하면서 데크의 오른쪽에 추가한다
◦
deque.extendleft(array) : 배열 array를 순환하면서 데크의 왼쪽에 추가한다
◦
deque.remove(x) : x를 데크에서 찾아 삭제한다
◦
deque.rotate(num) : 데크를 num만큼 회전한다 (양수면 오른쪽, 음수는 왼쪽으로)
heapq(우선순위 큐)
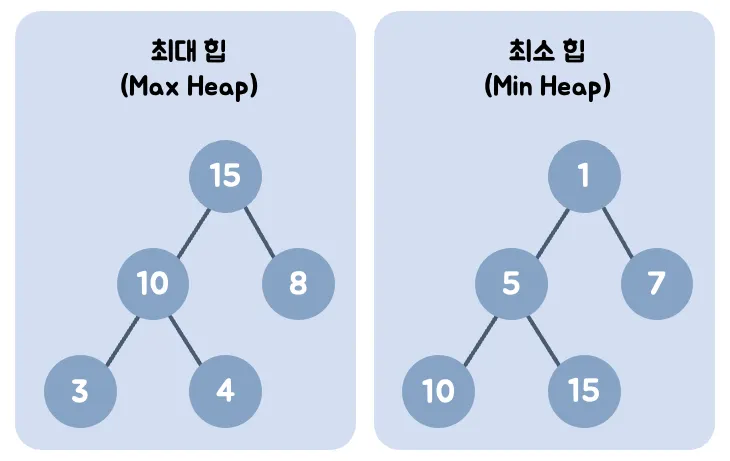
•
파이썬 heapq는 최소 힙으로 구현
•
최대 힙은 heappush 시 -1을 곱해주고, 출력 시 -1을 다시 곱해주면 됨.
import heapq
queue = []
heapq.heappush(queue, [2, 'A'])
heapq.heappush(queue, [5, 'B'])
heapq.heappush(queue, [1, 'C'])
heapq.heappush(queue, [7, 'D'])
print(queue) # 최소힙 이진탐색 리스트
for i in range(len(queue)):
print(heapq.heappop(queue)) # 최소값부터 추출
Python
복사
# heapify
import heapq
queue = [[2, 'A'], [5, 'B'], [1, 'C'], [7, 'D']]
heapq.heapify(queue) # 최소힙 이진탐색 리스트
print(queue)
for i in range(len(queue)):
print(heapq.heappop(queue))
Python
복사
리스트
•
.remove(x) : 리스트에서 첫 번째로 나오는 x값 삭제
•
.index(x) : num값의 인덱스 위치 찾기
•
del list[index] : 해당 인덱스에 있는 값 삭제, 인덱스 반환X
•
.pop(index) : 해당 인덱스에 있는 값 삭제, 인덱스 반환
•
.insert(index, num) : 해당 index에 num값 삽입
•
.append(x) : 맨 마지막에 x값 삽입
•
.extend(iterable) : 리스트 가장 바깥쪽 iterable의 모든 항목 삽입

•
.count(num) : num의 갯수
•
.reverse() : 뒤집기
•
reversed() : 뒤집기
•
2차원 리스트의 총 합 구하기
arr = [[1, 1, 0, 0], [1, 0, 0, 0], [1, 0, 0, 1], [1, 1, 1, 1]]
print(sum(sum(arr, []))) # 9
Python
복사
집합(set)
•
{} or set()
•
.add(x) : 세트에 요소 추가
•
.remove(x) : 특정 요소를 삭제하고, 없으면 에러 발생
•
.discard(x) : 특정 요소를 삭제하고, 없으면 그냥 넘어감
•
pop, clear, len, copy
딕셔너리
•
.get(key, {대체값}) : key의 value 습득, key가 존재하지 않을 경우 ‘대체값’ 출력
•
.pop(key) : key의 value값을 pop
•
key, value swap
dic = dict(zip('abcde', range(5)))
dic_swap = {v:k for k,v in dic.items()}
Python
복사
•
collections.defaultdict
◦
key가 없을시 default를 정해줌
from collections import defaultdict
d = defaultdict(lambda : 100)
d['hello'] = 1
print(d['hello'])
print(d['hi'])
print(d)
# 1
# 100
# defaultdict(<function __main__.<lambda>()>, {'hello': 1, 'hi': 100})
Python
복사
람다 (lambda)
•
람다의 기본 문법
lambda 매개변수 : 결과 # return 키워드 없이 자동으로 반환
Python
복사
•
배열 정렬
mylist = [[0,1], [2,1], [2,3], [3,1]]
mylist.sort(key=lambda x:x[1])
# mylist : [[0,1], [2,1], [3,1], [2,3]]
# 각 배열의 1번째 인덱스를 기준으로 정렬하게 된다.
mylist = [[0,1], [2,1], [2,3], [3,1], [-1,1], [2,2]]
mylist.sort(key=lambda x:(x[1], x[0]))
# mylist : [[-1,1]], [0,1], [2,1], [3,1], [2,1], [2,2], [2,3]])
Python
복사
할당
•
(아래 코드)반복문 속에서 append 할 때 주소가 now_h 객체를 가르키기 때문에 queue에 있는 모든 값들이 다 함께 변경 됨.
now_h[0] += dr[d_now % 4]
now_h[1] += dc[d_now % 4]
queue.append(now_h)
Python
복사
•
아래 코드처럼 해야 제대로된 queue가 뙴
now_h[0] += dr[d_now % 4]
now_h[1] += dc[d_now % 4]
queue.append([now_h[0], now_h[1]])
Python
복사
얕은 복사와 깊은 복사
•
얕은 복사(.copy())
mutable : 값이 변하는
immutable : 값이 변하지 않는
◦
mutable한 객체는 얕은 복사를 하면 새로운 주소값을 할당받음
◦
하지만 2차원 이상의 mutable 객체에서 안에 들어있는 각각의 객체들은, 겉에 있는 객체(복사한 새로운 객체)가 새로운 주소값을 할당받는다 해도
◦
그 안에 있는 각각의 mutable한 객체는 기존 객체 안에 있는 각각의 mutable한 객체를 가리키고 있기 때문에
◦
복사한 새로운 객체 값을 바꾸면 기존 객체의 요소들도 변경됨.
•
해결 방법
1.
copy 라이브러리 이용
import copy
new_obj = copy.deepcopy(기존 객체)
Python
복사
2.
2차원 리스트일 때 슬라이싱 이용 (1.5배 이상 속도 향상)
new_obj = [i[:] for i in 기존 리스트]
Python
복사
문자열
대/소문자 변환
•
.upper() : 모든 문자 변환
•
.lower() : 모든 문자 변환
•
.title() : 각 단어의 첫 글자만 대문자, 나머지는 소문자
•
.capitalize : 첫 글자만 대문자, 나머지는 소문자
문자열 탐색 (find, index, count)
•
.find('a') : 찾으면 인덱스 반환, 못찾으면 -1 반환
•
.index('a') : 찾으면 인덱스 반환, 못찾으면 오류 발생
•
.count('a', 3) : 특정 문자의 개수 반환(두번째 인자는 시작 인덱스를 의미)
문자열 구성 .is~
•
.isdigit() : 숫자로만 구성되어있는지
•
.isalpha() : 알파벳으로만 구성되어있는지(한글 포함)
•
.isupper() : 모두 대문자인지(숫자, 공백은 상관x)
•
.islower() : 모두 소문자인지(숫자, 공백은 상관x)
공백제거, 대체
(줄바꿈\n 이나 tab\t도 제거가 가능)
•
.strip() : 양쪽 끝 공백을 제거
•
.rstrip() : 오른쪽 끝 공백 제거
•
.lstrip() : 왼쪽 끝 공백 제거
•
.replace(a, b, n) : a문자를 b로 교체(n번 limit, limit가 없으면 전부 교체)
쪼개기, 합치기
•
.split() : 문자열 쪼개기
•
' '.join(문자열 리스트) : ' '을 사이에 끼고 합치기
포맷팅
•
f-string(python 3.6~) : 새로운 파이썬 포맷팅
◦
정수끼리 산술연산도 지원
◦
속도면에서도 가장 빠름
정규식
정규표현식에서 사용되는 메타 문자들
•
문자 클래스 [ ] : "[ ]사이의 문자들과 매치”를 의미
•
하이픈 - : 두 문자 사이의 범위(From - To)를 의미
◦
[a-zA-Z] : 알파벳 모두
◦
[0-9] : 숫자 모두 == \d
•
^ : 반대(not)를 의미
◦
\D == [^0-9] → 숫자가 아닌 것들을 의미
•
Dot . : 줄바꿈 문자인 \n을 제외한 모든 문자와 매치됨을 의미
◦
ex) a.b : “a+모든문자+b”
◦
ex) a[.]b : 정확히 “a.b”를 의미
•
반복 * : * 바로 앞에 있는 문자가 0부터 무한대로 반복될 수 있다는 의미
◦
ex) 정규식이 ca*t 일 때,
▪
“ct” : a가 0번 반복 → True
▪
“cat” : a가 1번 반복 → True
▪
“caat” : a가 2번 반복 → True
•
반복 + : + 바로 앞에 있는 문자가 1부터 무한대로 반복될 수 있다는 의미(은 0부터)
•
반복 {m,n} *:** m부터 n까지 반복 횟수가 고정적인 것을 찾음
◦
ex) ca{2}t
▪
“cat” : False
▪
“catt” : True
◦
ex) ca{2, 5}t
▪
“cat” : False
▪
“caaaat” : True
•
? : 바로 앞 글자가 있어도 되고, 없어도 됨을 의미
◦
ex) ca?t : “cat”, “ct” → True
re 모듈
•
match() : 문자열의 처음부터 정규식과 매치되는지 조사
import re
p = re.compile('[a-z]+')
m1 = p.match("python")
m2 = p.match("3 python")
print(m1)
print(m2)
# <re.Match object; span=(0, 6), match='python'>
# Match 객체를 돌려줌
# None
# None을 돌려줌
Python
복사
•
search() : 문자열 전체를 검색하여 정규식과 매치되는지 조사
import re
p = re.compile('[a-z]+')
m2 = p.search("3 python")
print(m2)
# <re.Match object; span=(2, 8), match='python'>
# 매치되는 부분을 찾아서 돌려줌
Python
복사
•
findall() : 정규식과 매치되는 모든 문자열을 리스트로 돌려줌
import re
p = re.compile('[a-z]+')
result = p.findall("life is too short")
print(result)
# 하단은 출력
['life', 'is', 'too', 'short']
Python
복사
•
finditer() : 정규식과 매치되는 모든 문자열을 반복 가능한 객체로 돌려줌
import re
p = re.compile('[a-z]+')
result = p.finditer("life is too short")
print(result)
# 하단은 출력
<callable_iterator object at 0x01F5E390>
Python
복사
for r in result: print(r)
# 하단은 출력
# match 객체로 출력됨
<re.Match object; span=(0, 4), match='life'>
<re.Match object; span=(5, 7), match='is'>
<re.Match object; span=(8, 11), match='too'>
<re.Match object; span=(12, 17), match='short'>
Python
복사
파이썬 컴프리핸션
# if
[i for i in range(1, 11) if i % 2 == 0] # 짝수만
Python
복사
# if ~ else
[i if i % 2 == 0 else 'No' for i in range(1, 11)]
Python
복사
파이썬 nonlocal, global
•
global : 전역 변수
•
nonlocal : 비지역(전역)변수
•
local : 지역 변수
# 스코프
global_var = "전역 변수"
print(global_var) # 전역 변수
def outer():
nonlocal_var = "비전역 변수"
global_var = "여기는 비전역변수"
print(global_var) # 여기는 비전역변수
print(nonlocal_var) # 비지역 변수
def inner():
local_var = "지역 변수"
nonlocal_var = "여기도 비전역 변수"
print(global_var) # 여기는 비전역변수
print(nonlocal_var) # 여기는 비지역 변수
print(local_var) # 지역 변수
inner()
print(nonlocal_var) ### 비전역 변수
outer()
print(global_var) ### 전역변수
Python
복사
# 스코프 변경
global_var = "전역 변수"
print(global_var) # 전역 변수
def outer():
nonlocal_var = "비전역 변수"
global global_var ### global 지정
global_var = "여기도 전역변수"
print(global_var) # 여기도 전역변수
print(nonlocal_var) # 비전역 변수
def inner():
local_var = "지역 변수"
nonlocal nonlocal_var ### nonlocal 지정
nonlocal_var = "여기도 비전역 변수"
print(global_var) # 여기도 전역변수
print(nonlocal_var) # 여기도 비전역 변수
print(local_var) # 지역 변수
inner()
print(nonlocal_var) ### 여기도 비전역 변수
outer()
print(global_var) ### 여기도 전역변수
Python
복사
python에서 말하는 시간
•
대략 2십만회 (200,000) 까지는 1초라고 생각해도 무관
