



What are Tensors?
•
텐서는 배열 및 행렬과 매우 유사한 특수 데이터 구조
•
스칼라, 벡터, 행렬, 다차원 배열 모두 텐서에 해당.
•
PyTorch에서는 텐서를 사용하여 모델의 입력과 출력은 물론 모델의 매개변수를 인코딩함.
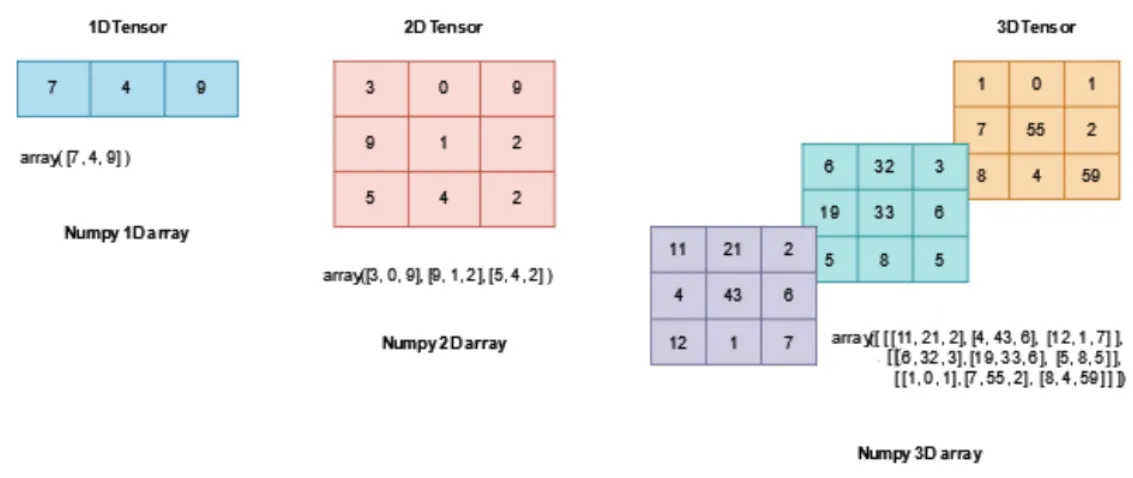
텐서의 특징
다차원 구조: 텐서는 0차원(스칼라)부터 여러 차원(다차원 배열)까지 다양한 구조를 가질 수 있습니다. 이를 통해 복잡한 데이터를 효율적으로 표현할 수 있습니다.
자동 미분(Auto Differentiation): 텐서를 사용하는 많은 딥러닝 프레임워크(예: PyTorch, TensorFlow)는 텐서의 자동 미분 기능을 제공합니다. 이를 통해 모델 학습 중 기울기를 자동으로 계산할 수 있습니다.
GPU 가속: 텐서는 GPU(그래픽 처리 장치)를 사용하여 대규모 병렬 연산을 수행할 수 있기 때문에, 딥러닝 모델의 학습 속도를 크게 향상시킵니다.
1. Tensor 생성
데이터에서 직접 생성
•
텐서 타입으로 형 변환 시켜야지 제대로 사용 가능함
data = [
[1, 2], [3, 4], [5, 6]
]
data
# [[1, 2], [3, 4], [5, 6]]
type(data)
# list
data = [
[1, 2], [3, 4], [5, 6]
]
data_tensor = torch.tensor(data)
data_tensor
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
data_tensor.shape
# torch.Size([3, 2])
type(data_tensor)
# torch.Tensor
Python
복사
Numpy 배열에서 생성
arr = np.array(data) # 리스트나 다른 데이터로부터 numpy 배열을 생성
arr # 생성된 numpy 배열을 출력
# array([[1, 2],
# [3, 4],
# [5, 6]])
type(arr) # 배열의 타입을 확인 (numpy.ndarray)
# numpy.ndarray
arr.shape # 배열의 형상(shape)을 확인 (3행 2열)
# (3, 2)
arr = np.array(data) # numpy 배열을 다시 생성
arr_tensor = torch.from_numpy(arr) # numpy 배열을 PyTorch 텐서로 변환
print(f'Numpy arr value: \n {arr} \n') # 변환 전의 numpy 배열을 출력
print(f'Tensor arr_tensor value: \n {arr_tensor}') # 변환된 PyTorch 텐서를 출력
# Numpy arr value:
# [[1 2]
# [3 4]
# [5 6]]
# Tensor arr_tensor value:
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
np.multiply(arr, 2, out=arr) # numpy 배열의 값을 2배로 곱한 결과를 다시 arr에 저장
print(f'Numpy arr after * 2 operation: \n {arr} \n') # 값이 2배로 변경된 numpy 배열을 출력
print(f'Tensor arr_tensor value after modifying numpy array: \n {arr_tensor}') # numpy 배열을 수정한 후 PyTorch 텐서의 값을 출력 (동기화됨)
# Numpy arr after * 2 operation:
# [[ 2 4]
# [ 6 8]
# [10 12]]
# Tensor arr_tensor value after modifying numpy array:
# tensor([[ 2, 4],
# [ 6, 8],
# [10, 12]])
Python
복사
다른 Tensor에서 생성
x_ones = torch.ones_like(data_tensor)
# ones_like()는 입력 텐서와 같은 속성(shape, dtype)을 유지하면서, 모든 값이 1인 새로운 텐서를 생성하는 메소드.
# 파라미터: data_tensor (입력 텐서)
x_ones # 생성된 1로 채워진 텐서를 출력
# tensor([[1, 1],
# [1, 1],
# [1, 1]])
x_rand = torch.rand_like(data_tensor, dtype=torch.float) # rand_like()는 입력 텐서와 같은 속성을 유지하면서, 0과 1 사이의 랜덤 값을 가지는 텐서를 생성하는 메소드.
# 여기서는 dtype 파라미터를 통해 data_tensor의 dtype을 float으로 변경함.
# 파라미터: data_tensor (입력 텐서), dtype=torch.float (데이터 타입을 float로 변경)
x_rand # 생성된 랜덤 값 텐서를 출력
# tensor([[0.9301, 0.7648],
# [0.3103, 0.4384],
# [0.1406, 0.5453]])
Python
복사
•
torch.ones_like(input):
◦
입력 텐서(input)와 동일한 크기(shape)와 데이터 타입(dtype)을 유지하면서, 모든 값이 1인 새로운 텐서를 반환
◦
파라미터:
▪
input: 기준이 되는 입력 텐서.
◦
주로 기존 텐서와 동일한 크기를 가진 1로 채워진 텐서를 만들고자 할 때 사용
•
torch.rand_like(input, dtype=None):
◦
입력 텐서(input)와 동일한 크기를 유지하면서, 0과 1 사이의 랜덤 값을 가지는 텐서를 생성.
◦
dtype 파라미터를 통해 데이터 타입을 변경할 수 있다.
◦
파라미터:
▪
input: 기준이 되는 입력 텐서.
▪
dtype: 텐서의 데이터 타입을 지정 (optional).
◦
사용 예: 초기 가중치 설정 또는 무작위 값을 생성해야 하는 경우에 주로 사용
무작위 또는 상수 값에서 생성
shape = (2,3,)
rand_tensor = torch.rand(shape) # shape에 맞는 0 ~ 1 사이의 랜덤 값을 가진 텐서를 생성한다.
rnad_normal_tensor = torch.randn(shape) # shape에 맞는 가우시안 정규분포를 따르는 랜덤 값을 가진 텐서를 생성한다.
ones_tensor = torch.ones(shape) # shape에 맞는 값이 1로 채워진 텐서를 생성한다.
zeros_tensor = torch.zeros(shape) # shape에 맞는 값이 0으로 채워진 텐서를 생성한다.
empty_tensor = torch.empty(shape) # shape에 맞는 초기화되지 않은 텐서를 생성한다.
print(f"Random Tensor: \n {rand_tensor} \n") # 0 ~ 1 사이의 숫자를 랜덤으로 생성한다.
print(f"Random Normal Distribution Tensor: \n {rnad_normal_tensor} \n") # 0 ~ 1 사이의 숫자를 가우시안 정규분포를 이용해 생성한다.
print(f"Ones Tensor: \n {ones_tensor} \n") # 값이 1로 채워진 텐서를 출력한다.
print(f"Zeros Tensor: \n {zeros_tensor}") # 값이 0으로 채워진 텐서를 출력한다.
print(f"Real Random Tensor: \n {empty_tensor}") # 특정한 값으로 초기화를 하지 않는 텐서를 출력한다.
Python
복사
Random Tensor:
tensor([[0.1029, 0.8244, 0.2781],
[0.9225, 0.4911, 0.8592]])
Random Normal Distribution Tensor:
tensor([[-0.5644, 0.4101, -0.1552],
[-0.3740, -1.0619, 0.1369]])
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
Real Random Tensor:
tensor([[1.4013e-45, 0.0000e+00, 1.5849e-42],
[0.0000e+00, 1.4013e-44, 0.0000e+00]])
Python
복사
•
torch.rand(shape)
◦
설명: 지정된 shape에 맞게 0과 1 사이의 균등 분포에서 무작위 값을 생성하는 텐서를 반환한다.
◦
파라미터: shape는 텐서의 크기를 지정하는 튜플이다. (2, 3)은 2x3 크기의 텐서를 생성한다.
◦
반환값: 주어진 크기의 텐서. 각 요소는 0과 1 사이의 값이다.
•
torch.randn(shape)
◦
설명: 지정된 shape에 맞게 평균이 0이고 분산이 1인 정규 분포(Gaussian distribution)를 따르는 무작위 값을 생성하는 텐서를 반환한다.
◦
파라미터: shape는 텐서의 크기를 지정하는 튜플이다.
◦
반환값: 주어진 크기의 텐서. 각 요소는 정규 분포를 따르는 값이다.
•
torch.ones(shape)
◦
설명: 지정된 shape에 맞게 모든 요소가 1로 초기화된 텐서를 생성한다.
◦
파라미터: shape는 텐서의 크기를 지정하는 튜플이다.
◦
반환값: 주어진 크기의 텐서. 모든 요소가 1이다.
•
torch.zeros(shape)
◦
설명: 지정된 shape에 맞게 모든 요소가 0으로 초기화된 텐서를 생성한다.
◦
파라미터: shape는 텐서의 크기를 지정하는 튜플이다.
◦
반환값: 주어진 크기의 텐서. 모든 요소가 0이다.
•
torch.empty(shape)
◦
설명: 지정된 shape에 맞게 메모리만 할당되고 초기화되지 않은 텐서를 생성한다. 초기값은 예측할 수 없다.
◦
파라미터: shape는 텐서의 크기를 지정하는 튜플이다.
◦
반환값: 주어진 크기의 텐서. 각 요소는 초기화되지 않은 값이다.
2. Tensor 속성
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
# Shape of tensor: torch.Size([3, 4])
# Datatype of tensor: torch.float32
# Device tensor is stored on: cpu
Python
복사
device
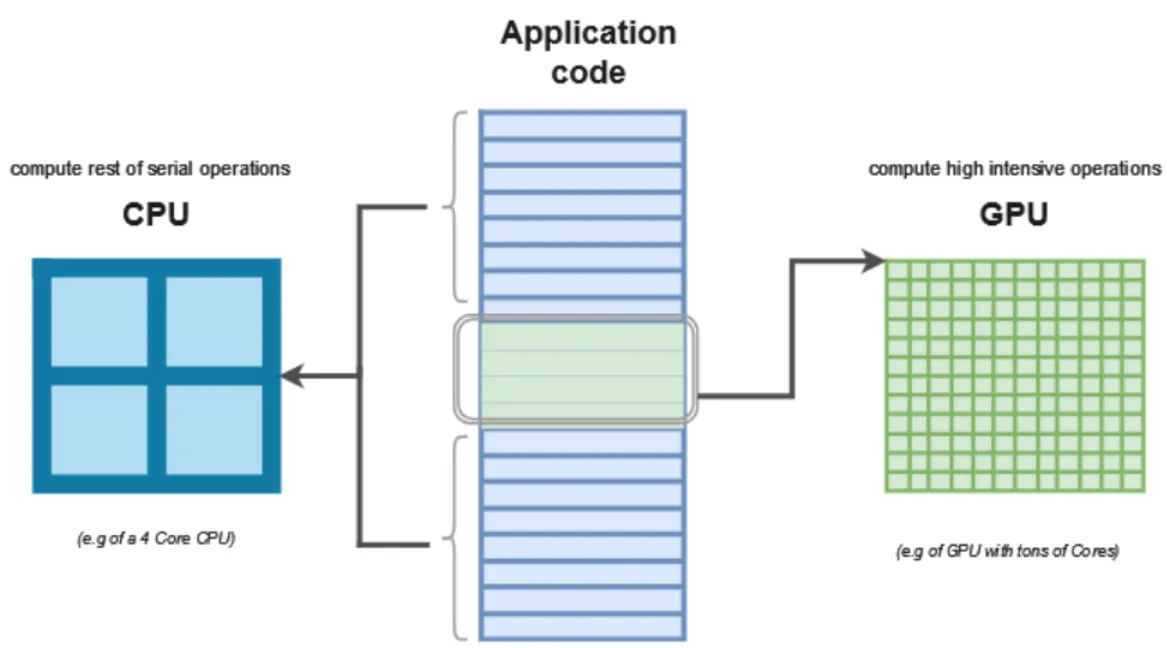
1.
Application Code (애플리케이션 코드):
•
중앙에 있는 직사각형은 애플리케이션 코드 전체를 나타낸다.
•
코드에는 다양한 종류의 연산 작업이 포함되어 있으며, 이를 적절히 분배하여 처리하는 것이 중요한 역할이다.
2.
CPU (Central Processing Unit):
•
왼쪽에 있는 파란색 블록은 CPU를 나타내며, 여기에는 4개의 코어가 있다(예시로 든 4코어 CPU).
CPU는 일반적으로 직렬 연산이나 상대적으로 덜 복잡한 연산을 처리하는 데 사용된다.
•
CPU는 직렬 연산(Serial Operations)을 처리한다고 나와 있다.
이는 병렬 처리가 아닌 순차적으로 처리해야 하는 작업을 CPU가 담당한다는 의미이다.
3.
GPU (Graphics Processing Unit):
•
오른쪽에 있는 녹색 격자 구조는 GPU를 나타낸다.
•
여기에는 수많은 코어가 있어, 대량의 병렬 연산이 가능하다.
GPU는 고강도 연산 작업(High-Intensive Operations)을 처리한다.
•
즉, 복잡한 수치 계산이나 대량의 데이터를 동시에 처리하는 데 특화되어 있다.
•
딥러닝, 이미지 처리와 같은 고성능 작업을 처리할 때 GPU가 효율적
# torch.cuda.is_available(): CUDA(GPU)가 사용 가능한지 여부를 확인하는 함수.
# 사용 가능한 GPU가 있으면 True를 반환하고, 그렇지 않으면 False를 반환한다.
if torch.cuda.is_available():
# tensor.to('cuda'): 텐서를 GPU로 이동시키는 메서드.
# 'cuda'는 GPU 디바이스를 의미하며, CPU에서 GPU로 연산을 옮긴다.
tensor = tensor.to('cuda')
# tensor.device: 해당 텐서가 위치한 디바이스(CPU 또는 GPU)를 반환.
# 이 값은 'cpu' 또는 'cuda'로 나올 수 있다.
tensor.device
# device(type='cpu')
Python
복사
3. Tensor 연산
Joining tensors - cat(), stack()
•
torch.cat()은 주어진 차원을 기준으로 주어진 텐서들을 붙힌(concatenate)다.
•
torch.stack()은 새로운 차원으로 주어진 텐서들을 붙힌다.
t1 = torch.tensor([[1, 2],
[3, 4]])
t2 = torch.tensor([[5, 6],
[7, 8]])
t1.shape, t2.shape
# (torch.Size([2, 2]), torch.Size([2, 2]))
Python
복사
torch.cat(tensors, dim)
torch.cat((t1, t2), dim=0) # dim=0 (행 방향)으로 텐서를 이어붙이기
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
torch.cat((t1, t2), dim=1) # dim=1 (열 방향)으로 텐서를 이어붙이기
tensor([[1, 2, 5, 6],
[3, 4, 7, 8]])
# dim=0으로 쌓기 (새로운 첫 번째 차원을 만들어서 텐서를 쌓는다)
stack_dim0 = torch.stack((t1, t2), dim=0) # 결과 텐서는 2x2x2 크기를 가진다.
tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
# dim=1으로 쌓기 (두 번째 차원을 기준으로 텐서를 쌓는다)
stack_dim1 = torch.stack((t1, t2), dim=1) # 결과 텐서는 2x2x2 크기를 가진다.
tensor([[[1, 2],
[5, 6]],
[[3, 4],
[7, 8]]])
Python
복사
torch.stack(tensors, dim)
•
설명
◦
여러 텐서를 새로운 차원으로 쌓아주는 메서드
◦
기존 텐서들의 차원을 유지하면서 추가적인 차원을 만들어서 결합한다.
•
파라미터:
◦
tensors: 쌓을 텐서들의 튜플 또는 리스트이다.
◦
dim: 새롭게 생성할 차원의 위치를 나타낸다.
▪
예를 들어 dim=0은 첫 번째 차원에 새 차원을 추가하고, dim=1은 두 번째 차원에 추가한다.
•
반환값: 주어진 차원에 새로운 차원을 추가한 텐서.
브로드캐스팅(Broadcasting)
•
PyTorch는 브로드캐스팅을 지원
•
크기가 다른 텐서 간의 연산도 가능하게 한다.
•
더 작은 텐서를 더 큰 텐서의 크기에 맞게 자동으로 확장하여 연산하는 기능
a = torch.tensor([1, 2, 3]) # 1차원 텐서
b = torch.tensor([[4], [5], [6]]) # 2차원 텐서 (3x1 크기)
result = a + b # a가 자동으로 확장되어 연산됨
print(result)
# 출력: [[5, 6, 7],
# [6, 7, 8],
# [7, 8, 9]]
Python
복사
산술연산(Arithmetic Operations)
행렬곱(torch.mm) - 브로드캐스팅 미지원
•
설명: 2차원 텐서(즉, 행렬) 간의 행렬 곱을 수행한다.
•
제한: 입력으로 주어지는 두 텐서는 반드시 2차원이어야 한다.
•
연산 방식: 표준 행렬 곱셈 (즉, 두 행렬의 내적을 수행).
import torch
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.mm(a, b)
print(result)
# 출력: [[19, 22],
# [43, 50]]
Python
복사
요소별 곱(torch.mul) - 브로드캐스팅 미지원
•
설명: 텐서 간의 요소별 곱을 수행. 각 위치의 대응되는 요소들끼리 곱해준다.
•
제한: 두 텐서는 같은 크기이거나 브로드캐스팅을 통해 크기가 맞춰질 수 있어야 한다.
•
연산 방식: 요소별 곱셈.
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.mul(a, b)
print(result)
# 출력: [[ 5, 12],
# [21, 32]]
Python
복사
배치 행렬 곱(torch.bmm)
•
설명
◦
배치(batch) 단위로 3차원 텐서의 행렬 곱을 수행
◦
3차원 텐서 와 의 두 텐서가 주어지면, 배치의 각 행렬끼리 곱셈을 수행하여 의 텐서를 반환
•
제한: 두 텐서는 3차원이어야 하며, 각각의 배치 내 행렬 크기가 맞아야 한다.
•
연산 방식: 각 배치마다 독립적인 행렬 곱을 수행.
a = torch.randn(2, 3, 4) # 크기 (2, 3, 4)
b = torch.randn(2, 4, 5) # 크기 (2, 4, 5)
result = torch.bmm(a, b)
print(result.size()) # 출력: torch.Size([2, 3, 5])
Python
복사
다차원 행렬 곱(torch.matmul)
•
설명
◦
다차원 텐서 간의 곱셈을 수행
◦
torch.matmul은 1차원, 2차원, 3차원 이상에서도 사용할 수 있으며, 차원에 따라 다른 방식으로 동작
•
제한: 텐서가 1차원 이상이어야 하며, 텐서의 차원에 따라 다르게 연산을 수행
•
연산 방식:
◦
1차원 텐서(벡터) 간: 내적.
◦
2차원 텐서(행렬) 간: 행렬 곱.
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
result = torch.matmul(a, b)
print(result)
# 출력: [[19, 22],
# [43, 50]]
Python
복사
◦
3차원 이상: 브로드캐스팅을 통해 배치 단위로 곱셈 수행.
a = torch.randn(2, 3, 4)
b = torch.randn(2, 4, 5)
result = torch.matmul(a, b)
print(result.size())
# 출력: torch.Size([2, 3, 5])
Python
복사
차이점 요약
함수 | 설명 | 제한 사항 | 연산 방식 |
torch.mm | 2차원 텐서(행렬) 간의 행렬 곱 | 2차원 텐서(행렬)만 사용 가능 | 행렬 곱셈 |
torch.mul | 요소별 곱 (element-wise multiplication) | 두 텐서의 크기가 같거나 브로드캐스팅 가능 | 요소별 곱 |
torch.bmm | 배치 단위 행렬 곱 | 3차원 텐서(배치)만 사용 가능 | 배치의 각 행렬 간 독립적 행렬 곱 수행 |
torch.matmul | 1D, 2D, 3D 이상에서 다차원 행렬 곱 수행 | 다차원 텐서에 사용 가능 | 차원에 따라 내적, 행렬 곱, 배치 곱 수행 |
Single-element tensors
•
하나의 값만을 포함하는 텐서
•
PyTorch에서 이러한 텐서는 종종 연산 결과로 나타난다.
•
예를 들어, 텐서 간의 합이나 곱의 결과가 단일 숫자일 때, 그 값은 single-element tensor로 반환된다.
Single-element tensor에서 값을 추출하는 방법 : .item()
single-element tensor에서 값을 추출하려면 .item() 메서드를 사용한다. 이 메서드는 텐서가 하나의 값만 포함하고 있을 때, 그 값을 파이썬의 기본 자료형(예: int, float)으로 반환한다.
import torch
# 하나의 요소만을 가진 텐서
x = torch.tensor([42.0])
# 값을 추출
value = x.item()
print(value) # 42.0 출력
Python
복사
•
.item()은 텐서의 스칼라 값을 추출할 때 사용하며, 단일 값만 포함한 텐서에 대해서만 사용할 수 있다.
연산에서 Single-element tensor
•
PyTorch에서 텐서 연산 결과가 하나의 숫자일 경우, 그것도 single-element tensor가 된다.
•
예를 들어, 텐서의 합이나 평균을 구할 때 이러한 텐서가 반환된다.
x = torch.tensor([1.0, 2.0, 3.0])
sum_value = x.sum() # single-element tensor 반환
print(sum_value) # tensor(6.) 출력
# 값을 추출
value = sum_value.item()
print(value) # 6.0 출력
Python
복사
주의 사항
•
다차원 텐서에서 .item()을 사용하려 하면 오류가 발생한다.
•
이 메서드는 단일 요소를 가진 텐서에만 사용 가능하다.
x = torch.tensor([1.0, 2.0, 3.0])
# x.item() # 오류 발생: 다차원 텐서에는 사용할 수 없다.
Python
복사
In-place operations
•
기존의 텐서 값을 직접 변경하는 연산
•
In-place 연산은 연산 결과를 새로운 텐서에 저장하지 않고, 기존의 텐서에 그 결과를 반영
•
In-place 연산은 메모리를 절약할 수 있지만, 잘못 사용할 경우 문제를 일으킬 수 있다.
In-place 연산의 특징
1.
기존 텐서의 값이 변경됨: In-place 연산을 수행하면 기존의 텐서 데이터가 바뀐다.
2.
메모리 절약: 새로운 텐서를 생성하지 않으므로 메모리를 덜 사용한다.
3.
연산 속도: 새로운 텐서를 생성하지 않기 때문에 메모리 할당 시간을 줄일 수 있다.
In-place 연산의 규칙
PyTorch에서 In-place 연산은 **연산자 뒤에 언더스코어(_)**가 붙는 것으로 표시된다. 예를 들어, add_(), mul_() 등의 연산이 있다.
import torch
# 텐서 생성
x = torch.tensor([1.0, 2.0, 3.0])
# In-place 덧셈 연산
x.add_(5) # x의 각 요소에 5를 더함
print(x) # tensor([6.0, 7.0, 8.0]) 출력
Python
복사
•
이 예에서 add_() 연산은 x 텐서의 값을 직접 변경한다. 새 텐서를 생성하지 않고, 기존의 텐서 x가 변경된다.
자주 사용되는 In-place 연산
•
덧셈(In-place addition): add_()
x.add_(value
Python
복사
•
곱셈(In-place multiplication): mul_()
x.mul_(value)
Python
복사
•
나눗셈(In-place division): div_()
x.div_(value)
Python
복사
•
제곱(In-place power): pow_()
x.pow_(value)
Python
복사
In-place 연산의 주의사항
1.
Autograd와의 상호작용
•
In-place 연산은 Autograd(자동 미분) 기능을 사용할 때 주의가 필요하다.
•
텐서가 Autograd의 계산 그래프에 포함되어 있을 때, In-place 연산을 수행하면 미분 계산에 문제가 발생할 수 있다.
2.
메모리 효율성 vs 안전성
•
In-place 연산은 메모리 효율성 면에서 유리하지만, 계산 그래프를 망가뜨릴 위험이 있다.
•
그래서 In-place 연산을 사용하는 경우에는 반드시 그래프 계산에 영향을 주지 않는 상황인지 확인해야 한다.
4. Bridge with Numpy
•
두 라이브러리 간의 데이터를 자유롭게 변환하는 기능
•
PyTorch와 NumPy는 모두 텐서 연산을 지원하며, PyTorch의 텐서와 NumPy 배열 간에 데이터 변환을 쉽게 할 수 있다.
•
PyTorch의 텐서를 NumPy 배열로 변환하거나 그 반대 작업을 통해 두 라이브러리의 장점을 동시에 사용할 수 있다.
PyTorch 텐서를 NumPy 배열로 변환
•
.numpy() 메서드 : 이 작업은 메모리를 공유하기 때문에, 한쪽에서 변경된 값은 다른 쪽에서도 영향을 미친다.
import torch
# PyTorch 텐서 생성
x = torch.tensor([1.0, 2.0, 3.0])
# 텐서를 NumPy 배열로 변환
x_numpy = x.numpy()
print(x_numpy) # [1. 2. 3.]
Python
복사
x.add_(1) # PyTorch 텐서 값을 변경
print(x) # tensor([2., 3., 4.])
print(x_numpy) # [2. 3. 4.] (NumPy 배열도 변경됨)
Python
복사
이 변환은 메모리 공유를 하기 때문에, x 텐서를 변경하면 x_numpy도 함께 변경된다.
NumPy 배열을 PyTorch 텐서로 변환
•
torch.from_numpy() 메서드 : NumPy 배열을 PyTorch 텐서로 변환
•
이 역시 메모리를 공유하기 때문에, 한쪽에서 수정하면 다른 쪽에도 영향을 미친다.
import numpy as np
import torch
# NumPy 배열 생성
x_numpy = np.array([1.0, 2.0, 3.0])
# NumPy 배열을 PyTorch 텐서로 변환
x_tensor = torch.from_numpy(x_numpy)
print(x_tensor) # tensor([1., 2., 3.], dtype=torch.float64)
Python
복사
x_numpy[0] = 10 # NumPy 배열 값 변경
print(x_numpy) # [10. 2. 3.]
print(x_tensor) # tensor([10., 2., 3.], dtype=torch.float64) (PyTorch 텐서도 변경됨)
Python
복사
NumPy 배열을 PyTorch 텐서로 변환하면 NumPy 배열과 메모리를 공유하기 때문에, 어느 쪽을 수정하더라도 서로에게 영향을 준다.
5. 차원 변경(Dimension Change)
•
텐서의 형태를 바꾸는 작업
view(): 텐서의 차원을 변경
•
view()는 텐서의 차원을 재구성하는데 사용된다.
•
이 함수는 새로운 모양으로 변환된 텐서를 반환하며, 데이터의 연속성을 요구한다.
import torch
# 2x3 텐서 생성
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
# 6x1 형태로 변경
x_view = x.view(6, 1)
print(x_view)
# 출력:
# tensor([[1],
# [2],
# [3],
# [4],
# [5],
# [6]])
Python
복사

주의: view()를 사용하려면 텐서가 **연속적(contiguous)**이어야 한다. 그렇지 않으면 오류가 발생하며, 이때 x.contiguous().view()를 사용해야 한다.
reshape(): 텐서의 모양을 재구성
•
reshape()는 view()와 유사하지만, 연속성이 보장되지 않아도 차원 변경을 수행할 수 있다.
•
필요하다면 데이터를 복사해서라도 모양을 맞추기 때문에 view()보다 유연하다.
x_reshape = x.reshape(6, 1)
print(x_reshape)
# 출력: view()와 동일
Python
복사
차이점: reshape()는 연속성이 보장되지 않아도 작동하며, 데이터를 복사하여 새로운 모양을 만들 수 있다.
squeeze(), unsqueeze() : 차원 변형
squeeze() : 차원(Dimension) 축소
•
squeeze()는 텐서에서 크기가 1인 차원을 제거한다.
•
1차원 이상의 경우에만 사용하며, 불필요한 차원을 줄일 때 유용하다.
x = torch.tensor([[[1], [2], [3]]]) # 크기 (1, 3, 1)
x_squeeze = x.squeeze()
print(x_squeeze)
# 출력:
# tensor([1, 2, 3])
# 크기: (3,)
Python
복사
unsqueeze() : 차원(Dimension)-배치 차원, 채널 차원 추가
•
unsqueeze()는 텐서의 특정 차원에 1을 추가하여 차원을 확장하는 데 사용된다.
•
이는 배치 차원이나 채널 차원(이미지)을 추가하는 데 자주 사용된다.
배치(batch) : 모델을 fitting할 때 훈련에 사용되는 데이터의 처리 단위
x = torch.tensor([1, 2, 3]) # 크기 (3,)
x_unsqueeze = x.unsqueeze(0)
print(x_unsqueeze)
# 출력:
# tensor([[1, 2, 3]])
# 크기: (1, 3)
Python
복사
transpose(), permute() : 텐서 차원의 순서 변경
transpose() : 2개의 차원 순서 변경
•
텐서의 차원 순서를 바꾼다. 예를 들어, 행과 열을 교환할 때 사용
•
딱 2 개의 차원을 맞교환할 수 있다.
x = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 2x3 텐서
x_transposed = x.transpose(0, 1)
print(x_transposed)
# 출력:
# tensor([[1, 4],
# [2, 5],
# [3, 6]])
Python
복사
permute() : 다차원(이미지) 순서를 변경
•
주어진 차원의 순서를 사용자가 지정한 대로 재배열하는 함수
•
주로 이미지 데이터를 다룰 때나 다차원 데이터를 처리할 때 유용하다.
•
여러 차원의 순서를 사용자 지정 방식으로 바꿀 수 있다. 3차원 이상의 텐서에서 특정한 순서로 차원을 재배열할 때 permute()를 사용한다.
import torch
# 크기가 (2, 3, 4)인 3차원 텐서 생성
x = torch.randn(2, 3, 4)
# 텐서의 차원 순서 변경
x_permuted = x.permute(2, 0, 1)
print(x.shape) # 원래 텐서의 크기: (2, 3, 4)
print(x_permuted.shape) # permute 후 텐서의 크기: (4, 2, 3)
Python
복사
•
permute()의 사용 예
◦
permute()는 이미지 데이터의 차원을 변경하는 데 자주 사용된다.
◦
예를 들어, 이미지 데이터는 보통 (채널, 높이, 너비) 순서로 되어 있는데, 이를 다른 형식인 (높이, 너비, 채널)로 바꾸고 싶을 때 사용한다.
