


설명

머신러닝 분석 모듈
머신러닝을 위한 다양한 알고리즘과 개발을 위한 편리한 프레임워크, API를 제공
주로 Numpy와 Scipy 기반 위에서 구축된 라이브러리
설치
> pip install scikit-learn
Shell
복사
자주 사용하는 사이킷런 모듈
import numpy as np ## 기초 수학 연산 및 행렬계산
import pandas as pd ## 데이터프레임 사용
from sklearn import datasets ## iris와 같은 내장 데이터 사용
from sklearn.datasets import make_classification ## 분류용 가상 데이터 만들기
from sklearn.model_selection import train_test_split ## train, test 데이터 분할
from sklearn.linear_model import LinearRegression ## 선형 회귀분석
from sklearn.linear_model import LogisticRegression ## 로지스틱 회귀분석
from sklearn.naive_bayes import GaussianNB ## 나이브 베이즈
from sklearn import svm ## 서포트 벡터 머신
from sklearn import tree ## 의사결정나무
from sklearn.ensemble import RandomForestClassifier ## 랜덤포레스트
import matplotlib.pyplot as plt ## plot 그릴때 사용
Python
복사
•
데이터 정제(Data Cleansing) & 속성 공학(Feature Engineering)
◦
sklearn.preprocessing: 데이터 전처리(인코딩, 정규화 등)
◦
sklearn.feature_selection: 특성 선택
◦
sklearn.feature_extraction: 특성 추출(아미지나 텍스트에서 속성 추출)
•
모델 성능 평가와 개선
◦
sklearn.model_selection: 데이터 분리, 하이퍼 파라미터 튜닝
◦
sklearn.metrics: 성능평가
•
지도학습(Supervised Learning)
◦
sklearn.ensemble: 앙상블
◦
sklearn.linear_model: 선형모델
◦
sklearn.tree: 의사결정나무
•
비지도학습(Unsupervised Learning)
◦
sklearn.cluster: 군집분석
◦
sklearn.decomposition: 차원축소
•
유틸리티와 데이터 세트
◦
sklearn.pipeline: 워크플로우 파이프라인
◦
예제 데이터 세트
•
사이킷런 알고리즘 명명규칙
◦
분류 알고리즘명: OOClassifier
◦
회귀 알고리즘명: OORegressor
ex) DecisionTreeClassifier
ex) DecisionTreeRegressor
내장된 예제 데이터 셋
•
datasets. loda_boston()
회귀 용도, 미국 보스턴의 집 피처들과 가격에 대한 데이터 셋
•
datasets. loda_breast_cancer()
분류 용도, 위스콘신 유방암 피처들과 악성/음성 레이블 데이터 셋
•
datasets. load_diabetes()
회귀 용도, 당뇨 데이터 셋
•
datasets. load_digits()
분류 용도, 0 ~ 9 까지의 숫자의 이미지 픽셀 데이터 셋
•
datasets. load_iris()
분류 용도, 붓꽃에 대한 피처를 가진 데이터 셋
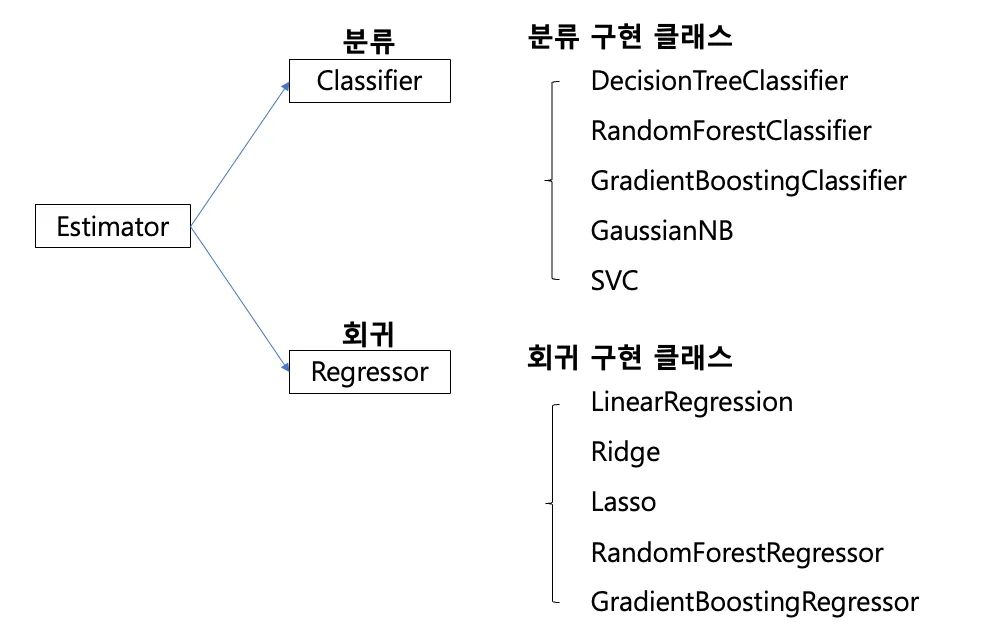
Estimator 클래스
•
분류 알고리즘 : Classifier
◦
DecisionTreeClassifier
◦
RandomForestClassifier
◦
GradientBoostingClassifier
◦
GaussianNB
◦
SVC
•
회귀 알고리즘 : Regressor
◦
LinearRegression
◦
Ridge
◦
Lasso
◦
RandomForestRegressor
◦
GradientBoostingRegressor
메서드
make_classfication(): 가상데이터 랜덤 생성
•
사용법
# 분류용 가상 데이터 만들기
from sklearn.datasets import make_classification
X, Y = make_classification(n_samples=1000, n_features=4,
n_informative=2, n_redundant=0,
random_state=0, suffle=False)
Python
복사
•
옵션
옵션명 | 설명 |
n_sample | 표본 수(default=100) |
n_features | 독립변수 수(default=20) |
n_informative | 종속변수와 상관관계가 존재하는 독립변수 수(default=2) |
n_redundant | 독립변수끼리 종속관계에 있는 독립변수 수(default=2) |
n_repeated | 중복 독립변수 수(default=0) |
n_classes | 종속변수 클래스(라벨) 수(default=2) |
n_clusters_per_class | 클래스당 클러스터 수(default=2) |
weights | 각 클래스에 할당 된 표본 수 |
random_state | 난수 생성 시드(seed) 번호 |
train, test 데이터 분할하기
•
오버피팅을 막기위해 데이터를 train, test로 분할
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.25, random_state=0)
Python
복사
•
옵션
옵션명 | 설명 |
test_size | test셋 비율 |
train_size | train셋 비율(default: 테스트셋의 나머지) |
random_state | 랜덤시드번호 |
suffle | 데이터섞기(default: true) |
statify | 라벨 비율 유지 |
모델 공통 API
fit(x_train, y_train) ## 모수 추정(estimat)
get_params() ## 추정된 모수 확인
predict(x_test) ## x_test로부터 라벨 예측
predict_log_proba(x_test) ## 로그 취한 확률 예측
predict_proba(x_test) ## 각 라벨로 예측될 확률
score(x_test, y_test) ## 모델 정확도 평가를 위한 mean accuracy
Python
복사
mean accuracy
각 라벨 종류별로 몇개를 맞췄는지를 표시
ex) 유방암 데이터에서 구분되는 라벨은 2가지
- 병에 걸리지 않았거나(=0)
- 걸린 경우(=1)|
스케일러

•
모든 피처들의 데이터 분포나 범위를 동일하게 조정
피처(feature)들마다 데이터값의 범위가 다 제각각이기 때문에 범위 차이가 클 경우 데이터를 갖고 모델을 학습할 때 0으로 수렴하거나 무한으로 발산하기 떄문에 스케일링이 필요
스케일러 방법 종류
•
~Scaler : 피처(feature)의 통계치를 이용 (열을 대상으로 함)
•
Normalizer : 행마다 정규화 진행
•
스케일링 전 정확도 (유방암 데이터셋)
import sklearn
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer_df = pd.DataFrame(data=cancer.data, columns=cancer.feature_names)
cancer_df['target'] = cancer.target
cancer_df.head()
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, test_size=0.2, random_state=3)
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
print('모델의 정확도 :', round(dtc.score(X_test, y_test), 4))
# 모델의 정확도 : 0.886
Python
복사
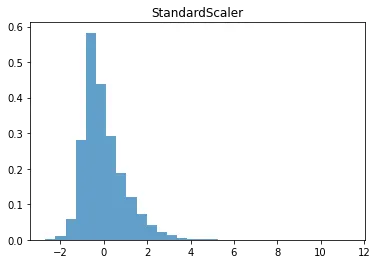
StandardScaler()
•
모든 피처들을 평균이 0, 분산이 1인 정규분포를 갖도록 만듬
•
표준화해주는 방법
데이터 내에 이상치가 있다면 데이터의 평균과 분산에 크게 영향을 주기 때문에 스케일링 방법으로 적절하지 않다.
•
스케일링
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
std.fit(X_train)
X_train_scaled = std.transform(X_train)
X_test_scaled = std.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))
# 모델의 정확도 : 0.9123
Python
복사
X_train_scaled.shape
# (455, 30)
# 데이터셋이 numpy array 이기 때문에 shape을 열 1개로 바꾸어서 플로팅
X_train_scaled_ss = X_train_scaled.reshape(13650,1)
X_train_data = X_train.reshape(13650,1)
Python
복사
◦
스케일링 전 훈련 데이터 셋 분포
plt.hist(X_train_data, bins=30, color= 'red', alpha = 0.7)
plt.title('before data scaling')
plt.show()
Python
복사

◦
스케일링 후 훈련 데이터 셋 분포
plt.hist(X_train_scaled_ss, bins=30, alpha = 0.7, density = True)
plt.title('StandardScaler')
plt.show()
Python
복사
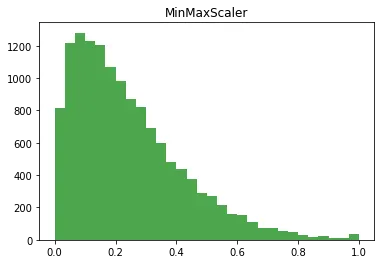
MinMaxScaler()
•
모든 피처들이 0과 1사이의 데이터값을 갖도록 만듬
•
피처별로 최솟값은 0이 되고, 최댓값은 1이 되는 것
•
데이터가 2차원인 겅우, 모든 데이터는 x, y 축의 0과 1 사이에 존재하게 된다.
데이터 내에 이상치가 존재한다면, 이상치가 극값이 되어 데이터가 아주 좁은 범위에 분포하게 되기 때문에 스케일링 방법으로 적절하지 않다.
•
스케일링
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler()
mms.fit(X_train)
X_train_scaled = mms.transform(X_train)
X_test_scaled = mms.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))
# 모델의 정확도 : 0.9035
Python
복사
X_train_scaled_mms = X_train_scaled.reshape(13650,1)
Python
복사
◦
스케일링 후 훈련 데이터 셋 분포
plt.hist(X_train_scaled_mms, bins=30, color='green', alpha = 0.7)
plt.title('MinMaxScaler')
plt.show()
Python
복사
MaxAbsScaler()
•
모든 피처들의 절댓값이 0과 1 사이에 놓이도록 만듬
•
0을 기준으로 절댓값이 가장 큰 수가 1또는 -1의 값을 가지게 된다.
이상치의 영향을 크게 받기 때문에 이상치가 존재할 경우 이 방법은 적절하지 않다.
•
스케일링
from sklearn.preprocessing import MaxAbsScaler
mas = MaxAbsScaler()
mas.fit(X_train)
X_train_scaled = mas.transform(X_train)
X_test_scaled = mas.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))
# 모델의 정확도 : 0.9123
Python
복사
X_train_scaled_mas = X_train_scaled.reshape(13650,1)
Python
복사
◦
스케일링 후 훈련 데이터 셋 분포
plt.hist(X_train_scaled_mas, bins=30, color='yellow', alpha = 0.7)
plt.title('MaxAbsScaler')
plt.show()
Python
복사

RobustScaler()
•
StandardScaler와 비슷
•
StandardScaler는 평균과 분산을 사용했지만 RobustScaler는 중간값(median)과 사분위값(quartile)을 사용
•
표준화 후 데이터가 더 넓게 분포해 있음
이상치의 영향을 최소화
•
스케일링
from sklearn.preprocessing import RobustScaler
rbs = RobustScaler()
X_train_scaled = rbs.fit_transform(X_train)
X_test_scaled = rbs.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))
# 모델의 정확도 : 0.9123
Python
복사
X_train_scaled_rbs = X_train_scaled.reshape(13650,1)
Python
복사
◦
스케일링 후 훈련 데이터 셋 분포
plt.hist(X_train_scaled_rbs, bins=30, color='pink', alpha = 0.7)
plt.title('RobustScaler')
plt.show()
Python
복사
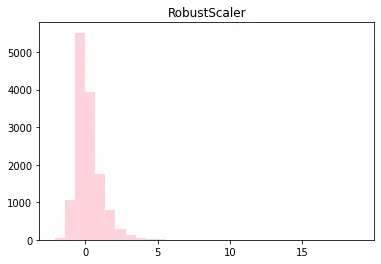
Normalizer()
•
각 행(row)마다 정규화가 진행
•
한 행의 모든 피처들 사이의 유클리드 거리가 1이 되도록 데이터값을 만듬
•
좀 더 빠르게 학습할 수 있고 과대적합 확률을 낮출 수 있음
•
x축의 범위도 가장 작다.
•
스케일링
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_train_scaled = norm.fit_transform(X_train)
X_test_scaled = norm.transform(X_test)
dtc.fit(X_train_scaled, y_train)
print('모델의 정확도 :', round(dtc.score(X_test_scaled, y_test), 4))
# 모델의 정확도 : 0.9298
Python
복사
X_train_scaled_norm = X_train_scaled.reshape(13650,1)
Python
복사
◦
스케일링 후 훈련 데이터 셋 분포
plt.hist(X_train_scaled_norm, bins=30, color='orange ', alpha = 0.7)
plt.title('Normalizer')
plt.show()
Python
복사

스케일러 메소드
fit()
•
머신러닝이 데이터에 머신러닝 모델을 맞추는 것(fit)
1.
학습데이터 세트에서 변환을 위한 기반 설정을 하는 함수
2.
데이터를 학습시키는 메서드
transform()
•
fit를 기준으로 얻는 mean, variance에 맞춰서 변형하는 것
1.
fit를 통해 세운 기반으로 변형하는 함수
2.
실제로 학습시킨 것을 적용하는 메서드
fit_transform()
•
상단의 두 기능을 합쳐놓은 것
•
train dataset에서만 fit_transform 혹은 fit, transform을 사용하는 이유
test set에서도 fit을 해버리면 sclaer가 기존에 학습 데이터에 fit한 기준을 다 무시하고 테스트 데이터에 새로운 mean, variance값을 얻으면서 테스트 데이터까지 학습하기 때문
테스트 데이터는 검증을 위해 남겨둔 셋이기 때문에 반드시 주의
분석 종류
LinearRegression: 선형회귀분석
clf = LinearRegression()
clf.fit(x_train,y_train) # 모수 추정
clf.coef_ # 추정 된 모수 확인(상수항 제외)
clf.intercept_ # 추정 된 상수항 확인
clf.predic(x_test) # 예측
clf.score(x_test, y_test) # 모형 성능 평가
Python
복사
LogisticRegression: 로지스틱 회귀분석
clf = LogisticRegression(solver='lbfgs').fit(x_train,y_train)
clf.predict(x_test)
clf.predict_proba(x_test)
clf.score(x_test,y_test)
Python
복사
GaussianNB: 나이브 베이즈
gnb = GaussianNB()
gnb.fit(x_train, y_train)
gnb.predict(x_test)
gnb.score(x_test, y_test)
Python
복사
DecisionTree: 의사결정 트리
clf = tree.DecisionTreeClassifier()
clf.fit(x_train, y_train)
clf.predict(x_test)
clf.predict_proba(x_test)
clf.score(x_test, y_test)
Python
복사
SVC: 서포트벡터머신
clf = svm.SVC(kernel='linear')
clf.fit(x_train, y_train)
clf.predict(x_test)
clf.score(x_test, y_test)
Python
복사
랜덤포레스트
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(x_train, y_train)
clf.feature_importances_
clf.predict(x_test)
Python
복사
