


설명

웹에서 가져온 HTML코드를 파이썬에서 사용하기 편하게 파싱해주는 라이브러리
설치
> python -m pip install --upgrade pip
> pip install beautifulsoup4
from bs4 import BeautifulSoup as bs
SQL
복사
웹에서 가져온 HTML 코드 가져오기
•
requests 모듈에서 가져와 파싱
custom_header = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"referer": "https://pann.ante.com/"
}
url = "https://pann.nate.com/talk/350939697"
response = requests.get(url, headers=custom_header)
response.raise_for_status()
Python
복사
•
urllib의 request 모듈에서 가져와 파싱
url = 'https://finance.naver.com/marketindex/'
site = req.urlopen(url)
page = site.read()
Python
복사
•
크롬 개발자 도구로 선택자 가져오기
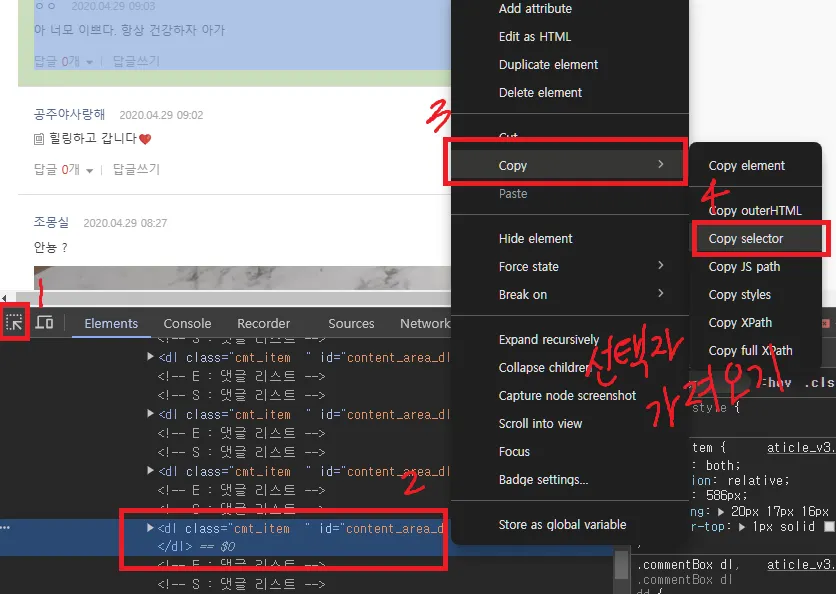
파싱하기 좋은 사이트
•
네이트판 :  네이트 판우리집 댕댕이 | 네이트 판
네이트 판우리집 댕댕이 | 네이트 판
네이트 판우리집 댕댕이 | 네이트 판•
벅스 뮤직 :  벅스!나를 위한 플리, 벅스
벅스!나를 위한 플리, 벅스
•
뉴스 기사 :  네이버 뉴스네이버 뉴스
네이버 뉴스네이버 뉴스
네이버 뉴스네이버 뉴스•
주식 WICS 코드 :  기아 - 네이버페이 증권 : 네이버페이 증권
기아 - 네이버페이 증권 : 네이버페이 증권
stock_code = "005930" # 삼성전자
url = "https://finance.naver.com/item/coinfo.naver?code={stock_code}".format(stock_code=stock_code)
custom_header = {
"referer": "https://finance.naver.com/item/main.naver/",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=custom_header)
soup = BeautifulSoup(req.text, "html.parser")
Python
복사
★ 참고 자료
메서드 → 객체
BeautifulSoup(html: str, “html.parser”) → BeautifulSoup 객체
•
HTML 문서를 파싱
•
HTML을 구성하고 있는 요소 및 태그 그리고 속성을 이해하고 트리 구조로 변환하여 데이터를 추출
.find()
•
HTML의 구조(=트리구조)에서 요소를 검색할 때
•
첫 번째 매치되는 요소를 반환, 없으면 None 반환
first_div = soup.find('div')
Python
복사
.find_all()
•
HTML의 구조(=트리구조)에서 요소를 검색할 때
•
매치되는 모든 요소를 리스트 형태로 반환
all_divs = soup.find_all('div')
Python
복사
.select_one()
•
CSS 선택자로 검색할 때 사용
•
첫 번째 매치되는 요소를 반환, 없으면 None 반환
h1 = soup.select_one('#course > h1')
print(h1.text)
Python
복사
.select()
•
CSS 선택자로 검색할 때 사용
•
일치하는 모든 요소를 리스트 형태로 반환
h1 = soup.select('#course > h1')
print(h1.text)
Python
복사
bs4 요약
#1. find
#첫 번째 매치되는 요소 반환
first_div = soup.find('div')
#2. find_all
#모든 요소 반환
all_divs = soup.find_all('div')
#3. select
#CSS 선택자를 사용하여 요소 선택
div_with_class = soup.select('.article')
#4. attrs
#요소의 속성에 접근
div_class = soup.find('div')['class']
#5. parent
#부모 요소에 접근
parent_div = soup.find('h1').parent
#6. find_next(), find_previous()
#다음 요소 혹은 이전 요소를 탐색
next_paragraph = soup.find('p').find_next('p')
#7. find_all_next(), find_all_previous()
#다음 요소 혹은 이전 요소를 모두 탐색
all_next_paragraphs = soup.find('p').find_all_next('p')
#8. strings
#요소 내의 모든 텍스트를 추출
text_pieces = soup.find('div').strings
Python
복사
이스케이프 문자 처리
•
개행 문자 및 탭 문자, 공백 제거를 활용하여 정리 정돈하는 방법
◦
replace("\n", "") : \n 개행문자(라인 피드, 다음 행으로 바꿈) 제거
◦
replace("\t", "") : \t 탭 문자 제거
◦
replace("\r", "") : \r 개행문자(캐리지 리턴, 커서를 행의 앞으로 이동) 재거
◦
strip() : 양쪽 공백 문자 제거
dd_list[0].get_text().replace("\n", "").replace("\t", "").replace("\r", "").strip()
for dd in dd_list:
print(dd.get_text().replace("\n", "").replace("\t", "").replace("\r", "").strip())
print("-"*80)
Python
복사
