


필수 라이브러리 임포트
# 필수 라이브러리
!pip install --upgrade joblib==1.1.0
!pip install --upgrade scikit-learn==1.1.3
!pip install mglearn
Python
복사
import logging
logging.getLogger('matplotlib.font_manager').setLevel(logging.ERROR)
import mglearn
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# import matplotlib.font_manager as fm
import seaborn as sns
# 브라우저에서 바로 그려지도록
%matplotlib inline
Python
복사
차원의 저주
•
데이터 학습을 위해 차원이 증가하면서 학습데이터 수가 차원의 수보다 적어져 성능이 저하되는 현상
•
차원이 증가할 수록 개별 차원 내 학습할 데이터 수가 적어지는(sparse) 현상 발생
•
해결책
◦
차원 축소
◦
데이터를 더 많이 수집해야함.
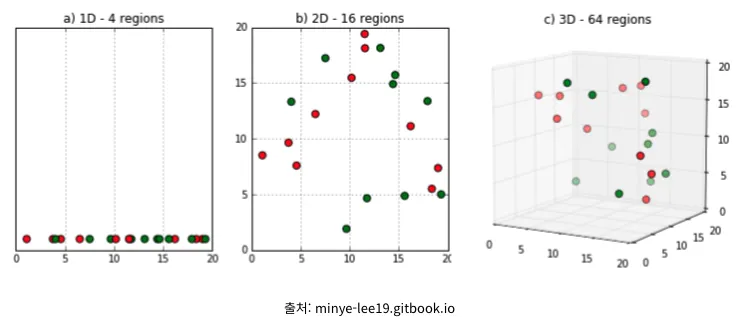
상기 이미지와 같이 데이터양은 동일하지만 차원만 늘어나면 빈공간이 많아지는 것을 볼 수 있다.
이것은 데이터 상에 0값으로 채워진 부분이 늘어난다는 뜻이다. 따라서 모델이 학습할 때, 상대적으로 데이터가 적어지므로, 성능이 저하될 수 밖에 없다.
특히 KNN과 같이 특정 알고리즘은 성능저하가 매우 심각해진다.
KNN 예제
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import OneHotEncoder
X, y = mglearn.datasets.make_forge()
X_tr, X_te, y_tr, y_te = train_test_split(X, y, random_state=0)
clf = KNeighborsClassifier(n_neighbors=3).fit(X_tr, y_tr)
print(f'훈련용 평가지표: {clf.score(X_tr, y_tr)} / 테스트용 평가지표: {clf.score(X_te, y_te)}')
# 훈련용 평가지표: 0.9473684210526315 / 테스트용 평가지표: 0.8571428571428571
Python
복사
print(f'before: {X.shape}')
enc = OneHotEncoder()
X_enc = enc.fit_transform(X)
print(f'after: {X_enc.shape}')
# before: (26, 2)
# after: (26, 52)
X_tr_enc, X_te_enc, y_tr, y_te = train_test_split(X_enc, y, random_state=0)
clf = KNeighborsClassifier(n_neighbors=3).fit(X_tr_enc, y_tr)
print(f'훈련용 평가지표: {clf.score(X_tr_enc, y_tr)} / 테스트용 평가지표: {clf.score(X_te_enc, y_te)}')
# 훈련용 평가지표: 0.9473684210526315 / 테스트용 평가지표: 0.42857142857142855
Python
복사
데이터 로드
import pandas as pd
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
from lightgbm import LGBMClassifier
import seaborn as sns
SEED = 42
df = sns.load_dataset('titanic')
df.shape
# (891, 15)
y_train = df["survived"] # 정답값
df = df.drop('survived', axis=1) # 정답값 제외
df.shape, y_train.shape
# ((891, 14), (891,))
# 결측치 미리 채우기
df.age = df.age.fillna(df.age.median()) # age 중앙값
df.deck = df.deck.fillna(df.deck.mode()[0]) # deck 최빈값
df.embarked = df.embarked.fillna(df.embarked.mode()[0]) # embarked 최빈값
df.embark_town = df.embark_town.fillna(df.embark_town.mode()[0]) # embark_town 최빈값
df.isnull().sum().sum()
# 0
Python
복사
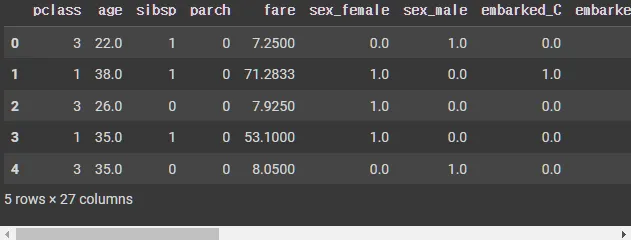
df.head()
# 학습에 바로 사용가능한 특성
cols = ["pclass","age","sibsp","parch","fare"]
features = df[cols]
print(f'before: {df.shape}')
# 범주형 one-hot encoding
cols = ["sex","embarked","class", "adult_male","deck", "embark_town", "alone"]
enc = OneHotEncoder()
sparse_features = pd.DataFrame(
enc.fit_transform(df[cols]).toarray(),
columns = enc.get_feature_names_out()
)
x_train = pd.concat([features,sparse_features],axis=1) # 특성
print(f'after: {x_train.shape}')
x_train.head()
# before: (891, 14)
# after: (891, 27)
Python
복사
Base model
model = LGBMClassifier(random_state=SEED)
cv = KFold(n_splits=5,shuffle=True,random_state=SEED)
scores = cross_val_score(model, x_train, y_train, cv = cv , scoring="roc_auc", n_jobs=-1)
base_score = scores.mean()
base_score
# 0.8789142777638352
Python
복사
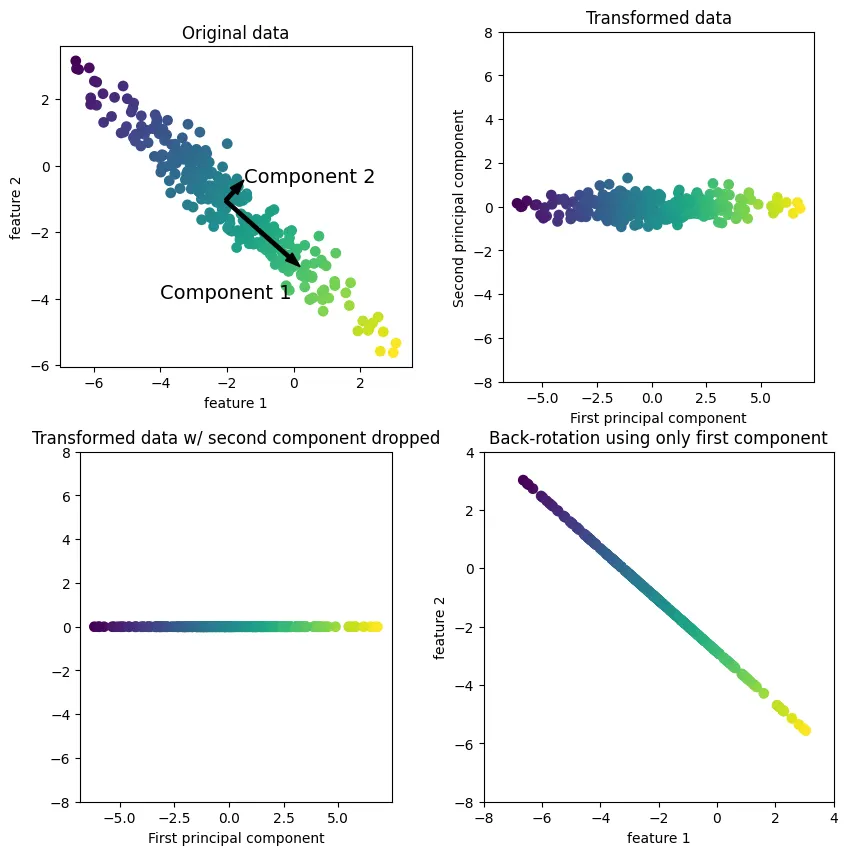
주성분 분석(PCA: Principal component Analysis)
•
특성들이 통계적으로 상관관계가 없도록 데이터셋을 회전시키는 기술
•
회전한 뒤에 데이터를 설명하는 데 얼마나 중요하냐에 따라 종종 새로운 특성 중 일부만 선택됩니다.
mglearn.plots.plot_pca_illustration()
Python
복사
•
주요 파라미터
◦
n_components: 주성분의 수
Base model(주성분 22)
from sklearn.decomposition import PCA
sparse_features.shape[1]
# 22
pca = PCA(n_components=sparse_features.shape[1], random_state=SEED)
pca.fit(sparse_features)
sum(pca.explained_variance_ratio_)
# 1.0
tmp = pd.DataFrame(pca.transform(sparse_features)).add_prefix("pca_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 27)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8719908209410917 / base_score: 0.8789142777638352
Python
복사
주성분 2인 경우
•
변수를 22개에서 2개로 줄였지만 성능에는 거의 차이가 없음
pca5 = PCA(n_components=2,random_state=SEED)
pca5.fit(sparse_features)
# 주성분에 의해 설명되는 분산비율
sum(pca5.explained_variance_ratio_)
# 0.5335179734922568
tmp = pd.DataFrame(pca5.transform(sparse_features)).add_prefix("pca_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 7)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8771644957872008 / base_score: 0.8789142777638352
Python
복사
주성분 15인 경우
•
변수를 15개로 줄였지만, 성능은 가장 좋지 않음
•
즉, 무조건 줄인다고 좋은 성능을 얻을 수 있지 않음
pca15 = PCA(n_components=15,random_state=SEED)
pca15.fit(sparse_features)
# 주성분에 의해 설명되는 분산비율
sum(pca15.explained_variance_ratio_)
# 0.9999999999999953
tmp = pd.DataFrame(pca15.transform(sparse_features)).add_prefix("pca_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 20)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc", n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8694994925466462 / base_score: 0.8789142777638352
Python
복사
특이값 분해(SVD; Singular Value Decomposition)
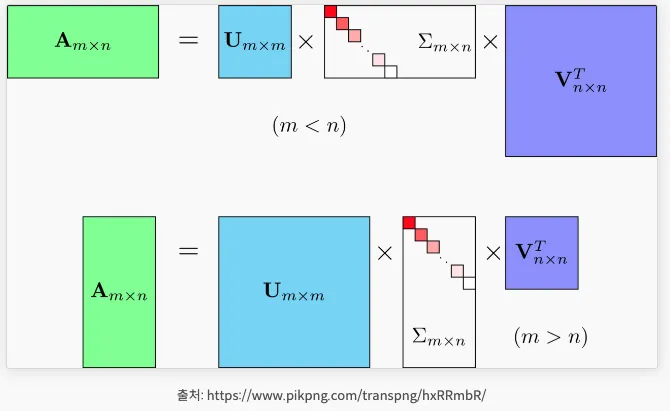
•
m x n 크기의 행렬 A는 m x m 크기의 형렬 U와 m x n 크기의 (합) 그리고 n x n 크기의(행렬 V의 전치행렬)로 나뉜다.
•
이렇게 행렬 A를 분해하는 것을 특이값 분해라고 한다.
특이값 분해 및 복원 실습
np.random.seed(121)
# 4x4 행렬 a 생성
a = np.random.randn(4,4)
np.round(a,3)
array([[-0.212, -0.285, -0.574, -0.44 ],
[-0.33 , 1.184, 1.615, 0.367],
[-0.014, 0.63 , 1.71 , -1.327],
[ 0.402, -0.191, 1.404, -1.969]])
Python
복사
특이값 분해
from numpy.linalg import svd
U, Sigma, Vt = svd(a) # 특이값 분행
print(U.shape, Sigma.shape, Vt.shape)
print('U matrix:\n',np.round(U, 3))
print('Sigma Value:\n',np.round(Sigma, 3))
print('V transpose matrix:\n',np.round(Vt, 3))
(4, 4) (4,) (4, 4)
U matrix:
[[-0.079 -0.318 0.867 0.376]
[ 0.383 0.787 0.12 0.469]
[ 0.656 0.022 0.357 -0.664]
[ 0.645 -0.529 -0.328 0.444]]
Sigma Value:
[3.423 2.023 0.463 0.079]
V transpose matrix:
[[ 0.041 0.224 0.786 -0.574]
[-0.2 0.562 0.37 0.712]
[-0.778 0.395 -0.333 -0.357]
[-0.593 -0.692 0.366 0.189]]
Python
복사
복원
# Sigma를 다시 0 을 포함한 대칭행렬로 변환
Sigma_mat = np.diag(Sigma)
a_ = np.dot(np.dot(U, Sigma_mat), Vt)
print(f'원본: {np.round(a,3)}')
print('-'*50)
print(f'복원: {np.round(a_, 3)}')
원본: [[-0.212 -0.285 -0.574 -0.44 ]
[-0.33 1.184 1.615 0.367]
[-0.014 0.63 1.71 -1.327]
[ 0.402 -0.191 1.404 -1.969]]
--------------------------------------------------
복원: [[-0.212 -0.285 -0.574 -0.44 ]
[-0.33 1.184 1.615 0.367]
[-0.014 0.63 1.71 -1.327]
[ 0.402 -0.191 1.404 -1.969]]
Python
복사
기존 a행렬과 값이 같은 것을 확인할 수 있다.
Base model
•
TruncatedSVD
◦
Sigma 행렬에 있는 대각원소, 즉 특이값 중 상위 일부 데이터(n_components)만 추출해 분해하는 방식이다.
sparse_features.shape[1]
# 22
from sklearn.decomposition import TruncatedSVD
svd = TruncatedSVD(n_components=sparse_features.shape[1],random_state=SEED)
svd.fit(sparse_features)
sum(svd.explained_variance_ratio_)
# 0.999999999999995
tmp = pd.DataFrame(svd.transform(sparse_features)).add_prefix("svd_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 27)
model = LGBMClassifier(random_state=SEED)
base_score = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1).mean()
print(f'base_score: {base_score}')
# base_score: 0.8697713324704475
Python
복사
주성분이 5인 경우
svd5 = TruncatedSVD(n_components=5,random_state=SEED)
svd5.fit(sparse_features)
sum(svd5.explained_variance_ratio_)
# 0.798802918363707
tmp = pd.DataFrame(svd5.transform(sparse_features)).add_prefix("svd_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 10)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8732002749842204 / base_score: 0.8697713324704475
Python
복사
주성분이 15인 경우
svd15 = TruncatedSVD(n_components=15,random_state=SEED)
svd15.fit(sparse_features)
sum(svd15.explained_variance_ratio_)
# 0.999999999999995
tmp = pd.DataFrame(svd15.transform(sparse_features)).add_prefix("svd_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 20)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8701293762766819 / base_score: 0.8697713324704475
Python
복사
비음수 행렬 분해(NMF; Non-negative Matrix Factorization)
비음수 행렬 인수분해라고 불리는 이유는 음수가 아닌 특성과 가중치를 반환하기 때문이다.
•
NMF는 원본 행렬 내의 모든 원소 값이 모두 양수라는 것이 보장되면 다음과 같은 좀 더 간단하게 두 개의 기반 양수 행렬로 분해 될 수 있는 기법을 지칭
•
NMF도 SVD와 유사하게 이미지 압축을 통한 패턴 인식 등에 잘 사용
또한 영화 추천과 같은 추천 영역에 활발하게 적용
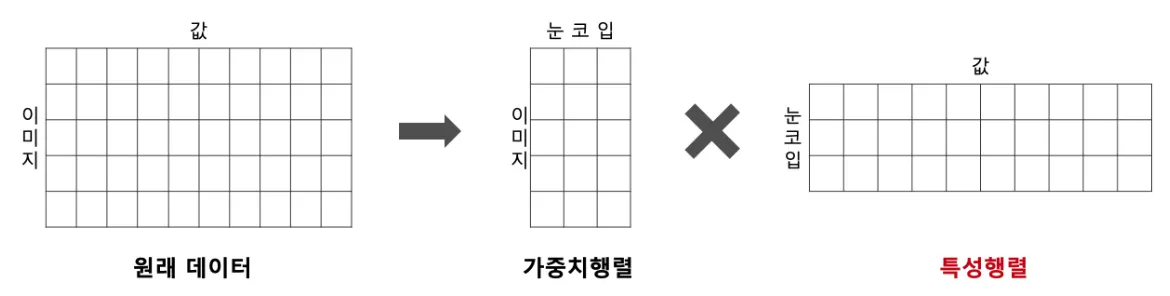
Base model
from sklearn.decomposition import NMF
nmf = NMF(n_components=sparse_features.shape[1], random_state=SEED, max_iter=500)
nmf.fit(sparse_features)
Python
복사

(nmf.components_ < 0).sum(), nmf.components_.shape
# (0, (22, 22))
tmp = pd.DataFrame(nmf.transform(sparse_features)).add_prefix("nmf_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 27)
model = LGBMClassifier(random_state=SEED)
base_score = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1).mean()
print(f'base_score: {base_score}')
# base_score: 0.8708822437925263
Python
복사
주성분 5인 경우
nmf5 = NMF(n_components=5, random_state=SEED, max_iter=500)
nmf5.fit(sparse_features)
Python
복사

(nmf5.components_ < 0).sum(), nmf5.components_.shape
# (0, (5, 22))
tmp = pd.DataFrame(nmf5.transform(sparse_features)).add_prefix("nmf_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 10)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8733993241464184 / base_score: 0.8708822437925263
Python
복사
주성분 15인 경우
nmf15 = NMF(n_components=15, random_state=SEED, max_iter=500)
nmf15.fit(sparse_features)
Python
복사

(nmf15.components_ < 0).sum(), nmf15.components_.shape
# (0, (15, 22))
tmp = pd.DataFrame(nmf15.transform(sparse_features)).add_prefix("nmf_")
x_train = pd.concat([features,tmp],axis=1)
print(f'after: {x_train.shape}')
# after: (891, 20)
model = LGBMClassifier(random_state=SEED)
scores = cross_val_score(model,x_train,y_train,cv = cv , scoring="roc_auc",n_jobs=-1)
print(f'score: {scores.mean()} / base_score: {base_score}')
# score: 0.8725423681482987 / base_score: 0.8708822437925263
Python
복사
