Data Encoding
•
머신러닝 알고리즘은 문자열 데이터 속성을 입력받지 못하며, 모든 데이터는 숫자형으로 입력받아야 한다.
•
따라서, 문자형 카테고리 속성은 모두 숫자형으로 변환이 되어야 하는데, 이러한 과정을 데이터 인코딩
설치
!pip install category_encoders
Python
복사
import numpy as np
import pandas as pd
import category_encoders as ce
Python
복사
변수 유형
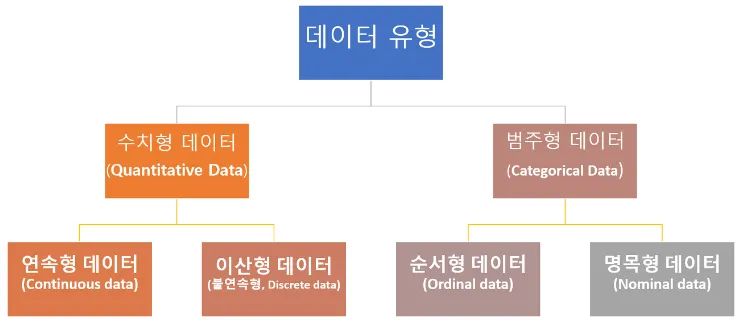
종류

•
종류
◦
Norminal Encoding : 순서 정보가 없는 데이터
▪
One hot Encoding
▪
Mean Encoding
◦
Ordinal Encoding : 순서 정보가 있는 데이터
▪
Label Encoding
▪
Target Encoding
▪
Ordinal Encoding
•
예)
◦
순서정보가 있는 데이터: 과목 성적, 영화 평점...
◦
순서정보가 없는 데이터: 성별, 혈액형....
Norminal Encoding
One hot Encoding
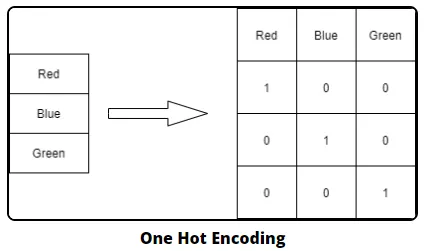
•
feature 값의 유형에 따라 새로운 feature를 추가해 고유 값에 해당하는 column에만 1을 표시, 나머지 column에만 1을 표시, 나머지 column에는 0을 표시하는 방식
•
즉, 행 형태로 되어있는 feature의 고유 값을 열 형태로 차원을 변환함
→ 고유값에 해당하는 column에만 1, 나머지 column에는 0을 표시
•
One-Hot Encoding은 sklearn에서 OneHotEncoder Class로 쉽게 변환 가능
•
주의
◦
OneHotEncoder로 변환하기 전에 모든 문자열 값이 숫자형 값으로 변환되어야 함 (LabelEncoder가 선행되는 것)
◦
입력 값으로 2차원(매트릭스) 데이터가 필요함
◦
0은 학습에 도움이 안됌
•
피처의 항목이 많은 경우 차원의 저주에 빠질 수 있다.
•
category_encoders을 이용한 인코딩
encoder = ce.OneHotEncoder(use_cat_names=True) # 인코딩 객체 만들어짐.
df_encoded = encoder.fit_transform(df) # 인코딩 객체가 fit, transform....
df_encoded.head() # transform 결과 보기
Python
복사
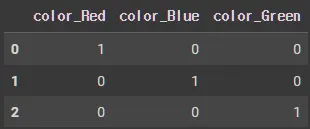
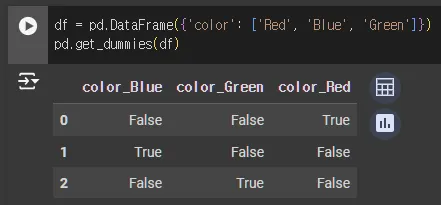
get_dummies = 손쉬운 버전의 One-Hot Encoding

•
pandas의 get_dummies : One-Hot Encoding을 더 쉽게 제공
•
LabelEncoding 과정을 거칠 필요 없이 (문자열 카테고리 값을 숫자 형으로 변환할 필요 없이) 즉시 사용 가능
df = pd.DataFrame(data)
pd.get_dummies(df)
Python
복사
Mean Encoding
•
각 카테고리의 값을 학습 데이터의 target 값의 평균값으로 설정하는 것

•
카테고리형 피처가 매우 많은 종류의 카테고리를 가지고 있을 때
•
One-Hot 인코딩을 할 경우 새로운 컬럼이 너무 많이 생기게 되고 High Cardinality Feature를 모델에 너무 불균형하게 중요하게 만들어 Column Sampling 과정에 안 좋은 영향을 끼치게 된다.
•
그리고 보통 Feature Engineering 과정에서 Feature들을 서로 결합해 새로운 Feature를 생성하는데 이때, 새로운 High Cardinality Feature가 생성되게 만든다.
•
그렇기 때문에 High Cardinality 카테고리형 피처를 숫자형으로 인코딩하기 위해 적합한 인코딩 방법이 필요하고 그것이 바로 Mean target 인코딩이다.
•
주의
◦
구분이 명확하진 않다.
◦
과적합(Overfitting): Mean Target 인코딩은 타겟 값에 대한 정보를 직접적으로 사용하기 때문에, 모델이 훈련 데이터에 과도하게 적응하는 과적합의 위험이 있습니다. 이를 방지하기 위해 교차 검증(Cross-validation)이나 스무딩(Smoothing) 같은 기법을 적용할 수 있다.
•
해결 방법
◦
교차 검증: Mean Target 인코딩을 적용할 때, 훈련 데이터를 여러 개의 폴드로 나누고 각 폴드의 평균을 사용하여 다른 폴드의 값을 인코딩한다.
◦
스무딩: 작은 샘플 크기에서의 노이즈를 줄이기 위해, 범주형 변수의 평균을 전체 타겟 평균과 결합하여 스무딩된 값을 사용한다.
Mean Encoding vs Label Encoding
•
Mean Target 인코딩:
◦
원리: 범주형 변수의 각 카테고리 값에 대해 해당 카테고리에 속하는 데이터의 타겟 값(예측하려는 목표 변수)의 평균을 계산하여, 그 평균 값으로 해당 카테고리를 수치화하는 기법
◦
예시:
▪
product_type이라는 범주형 변수가 있고, 이 변수의 값으로 "A", "B", "C"가 있다고 가정할 때, 각 제품 유형에 대해 판매 여부(0 또는 1)를 예측하려고 한다면, 각 제품 유형에 해당하는 판매 여부의 평균값을 계산하여 그 값으로 product_type 변수를 인코딩한다.
▪
"A" 유형의 10개의 제품 중 7개가 판매되었다면, "A"는 0.7로 인코딩된다.
◦
장점
▪
이 기법은 타겟 값과 직접적으로 연관된 정보를 반영하기 때문에, 모델이 카테고리와 타겟 사이의 관계를 더 잘 학습할 수 있다.
▪
이로 인해 인코딩된 값들이 less bias(적은 편향성)를 가지게 된다.
•
Label 인코딩:
◦
원리: 범주형 변수의 각 카테고리 값을 고유한 정수로 변환하는 기법입니다.
◦
예시:
▪
product_type 변수가 "A", "B", "C"라는 값을 가진다면, "A"는 0, "B"는 1, "C"는 2로 인코딩됩니다.
◦
단점
▪
Label 인코딩의 경우, 변환된 정수 값이 순서를 가지게 되어, 모델이 이 순서를 실제 의미가 있는 것으로 해석할 수 있다.
▪
이로 인해 선형 회귀와 같은 모델에서 문제를 일으킬 수 있다.
▪
예를 들어, 모델은 "A" (0)가 "B" (1)보다 작고, "B"는 "C" (2)보다 작다는 잘못된 가정을 하게 됩니다.
Ordinal Encoding
•
훈련 데이터에 나타나는 범주값들을 (사전순으로 정렬한 뒤) 서수로 변환 (0, 1, 2, …)
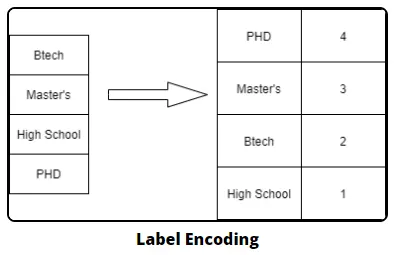
Label Encoding
•
n개의 범주형 데이터를 0부터 n-1까지의 연속적 수치 데이터로 표현하는 것
•
인코딩 결과가 수치적인 차이를 의미하진 않음.
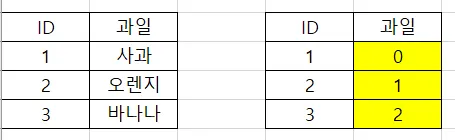
◦
레이블 인코딩은 문자열 값을 숫자형 카테고리 값으로 변환해주는 것
•
이를 ML알고리즘에 적용할 경우 예측 성능이 떨어지는 경우가 있어 선형 회귀 등의 알고리즘에는 적용하지 않음
•
주로 트리 계열의 알고리즘에서 사용
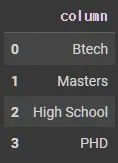
data = {'column': ['Btech', 'Masters', 'High School', 'PHD']}
df = pd.DataFrame(data)
df.head()
Python
복사
sklearn을 이용한 인코딩
from sklearn.preprocessing import LabelEncoder
Python
복사
encoder = LabelEncoder()
df['column_encoded'] = encoder.fit_transform(df['column'])
df.head()
Python
복사
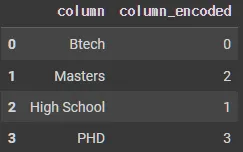
df['column'].unique()
# array(['Btech', 'Masters', 'High School', 'PHD'], dtype=object)
encoder.classes_
# array(['Btech', 'High School', 'Masters', 'PHD'], dtype=object)
encoder.inverse_transform([0,1])
# array(['Btech', 'High School'], dtype=object)
Python
복사
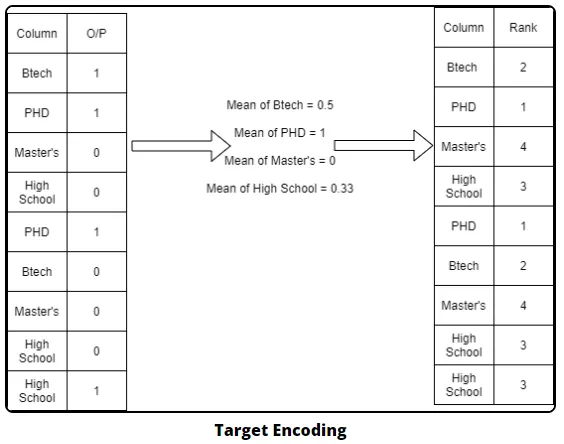
Target Encoding
•
해당 Category에 나타난 Target Variable의 평균을 이용해서 Categorical Values를 대체하는 방식
•
범주형 변수의 각각의 범주를 타겟 변수의 특정 통계치, 예를 들어 타겟값 평균으로 변환하는 방식
•
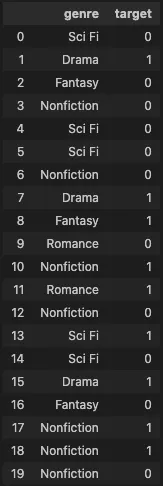
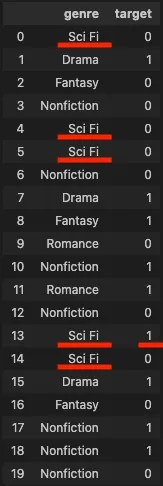
다음과 같은 genre 카테고리 별 이진 target 값을 갖는 데이터 셋이 있을때
•
"Sci Fi" genre에 대한 인코딩 값은 ("Sci Fi" genre 중 target이 1인 수) / ("Sci Fi" genre 수), 즉, 1/5이 된다.
import pandas as pd
import numpy as np
np.random.seed(123)
target = list(np.random.randint(0, 2, 20))
genres = ["Sci Fi", "Drama", "Romance", "Fantasy", "Nonfiction"]
genre = [genres[i] for i in np.random.randint(0, len(genres), 20)]
df = pd.DataFrame({"genre": genre, "target": target})
df
Python
복사
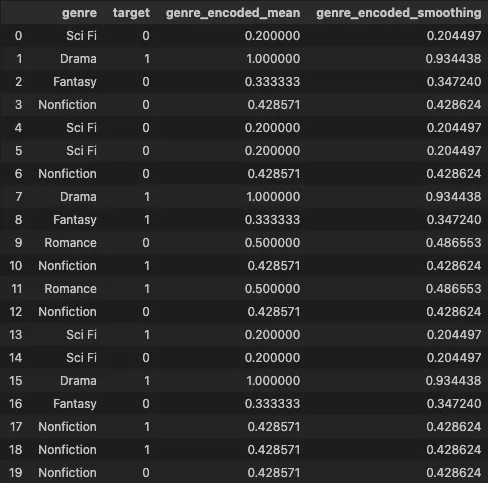
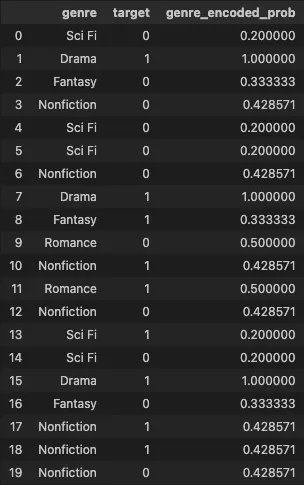
•
기존 데이터셋과 합친 모습
categories = df['genre'].unique()
targets = df['target'].unique()
cat_list = []
for cat in categories:
aux_dict = {}
aux_dict['category'] = cat
aux_df = df[df['genre'] == cat]
counts = aux_df['target'].value_counts()
aux_dict['count'] = sum(counts)
for t in targets:
aux_dict['target_' + str(t)] = counts[t] if t in counts else 0
cat_list.append(aux_dict)
cat_df = pd.DataFrame(cat_list)
cat_df['genre_encoded_prob'] = cat_df['target_1'] / cat_df['count']
cat_df
Python
복사
Smoothing 처리
•
평균값은 각각의 범주 단위로 계산되는데, 해당 범주 개수가 적을 경우 극단적으로 0 또는 1에 가깝게 나올 수 있다.
•
이를 완화하기 위해 전체 평균값을 일정 비율 섞을 수 있는데, 이를 smoothing이라고 한다.
•
smoothing 정도를 결정하는 αα 파라미터를 사용하여 다음과 같이 계산이 가능하다.
•
값은 보통 다음 값을 사용
◦
f: smoothing_factor
◦
k: min_samples_leaf
smoothing_factor = 1.0 # The f of the smoothing factor equation
min_samples_leaf = 1 # The k of the smoothing factor equation
prior = df['target'].mean()
smoove = 1 / (1 + np.exp(-(stats['count'] - min_samples_leaf) / smoothing_factor))
smoothing = prior * (1 - smoove) + stats['mean'] * smoove
encoded = pd.Series(smoothing, name = 'genre_encoded_smoothing')
df4 = df3.join(encoded, on='genre')
df4
Python
복사