



예제 데이터 로드
결과 저장
results = []
Python
복사
모델 정의
from sklearn.tree import DecisionTreeClassifier
SEED = 42
Python
복사
데이터 로드
import seaborn as sns
df = sns.load_dataset('titanic')
cols = ["age","sibsp","parch","fare","pclass","sex","embarked", "survived"]
df = df[cols]
df.shape
# (891, 8)
Python
복사
데이터 분리
from sklearn.model_selection import train_test_split
SEED=42
train, test = train_test_split(df, random_state=SEED, test_size=0.2)
train.shape, test.shape
# ((712, 8), (179, 8))
Python
복사
결측치 제거
train.age = train.age.fillna(train.age.mean())
test.age = test.age.fillna(train.age.mean())
train['embarked'] = train.embarked.fillna(train.embarked.mode().values[0])
test.embarked = test.embarked.fillna(train.embarked.mode().values[0])
train.isnull().sum().sum()
# 0
Python
복사
cols = ["age","fare"]
features_tr = train[cols]
target_tr = train["survived"]
features_te = test[cols]
target_te = test["survived"]
features_tr.shape, target_tr.shape
# ((712, 2), (712,))
Plain Text
복사
cols_encoding = ["pclass","sex","embarked","sibsp","parch"]
tmp_tr = train[cols_encoding]
tmp_te = test[cols_encoding]
tmp_tr.shape
# (712, 5)
Python
복사
tmp_tr.head()
Python
복사
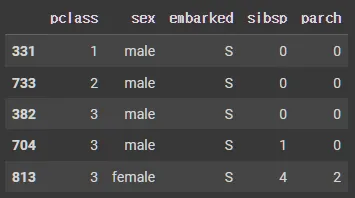
tmp_tr['sex'] = tmp_tr['sex'].map({'male':1, 'female':0})
tmp_tr['embarked'] = tmp_tr['embarked'].map({'S':2, 'C':1, 'Q':0})
tmp_te['sex'] = tmp_te['sex'].map({'male':1, 'female':0})
tmp_te['embarked'] = tmp_te['embarked'].map({'S':2, 'C':1, 'Q':0})
Plain Text
복사
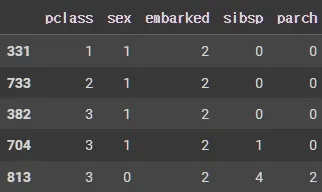
tmp_tr.head()
Python
복사
잔여 결측치 확인
tmp_tr.isnull().sum().sum(), tmp_te.isnull().sum().sum()
# (0, 0)
Python
복사
One hot Encoding
인코더 생성
encoder = ce.OneHotEncoder(use_cat_names=True)
Python
복사
범주형 변수들을 One hot Encoding 방식으로 변환하여 새로운 데이터프레임 enco_tr과 enco_te에 저장
# 초기화
enco_tr = pd.DataFrame()
enco_te = pd.DataFrame()
for col in tmp_tr.columns: # tmp_tr의 각 열(col)에 대해 반복
_enco = encoder.fit_transform(tmp_tr[col].astype('category')) # 훈련 데이터 인코딩
enco_tr = pd.concat([enco_tr, _enco], axis=1)
# encoder.fit_transform : tmp_tr의 특정 컬럼을 인코딩
# fit_transform : 인코더가 데이터를 학습하고, 동시에 해당 데이터를 인코딩된 값으로 변환
# astype('category') : 데이터를 범주형으로 변환하여, 인코딩이 가능한 형태로 만든다.
# 인코딩된 결과는 _enco에 저장되고, enco_tr에 열 방향(axis=1)으로 추가
_enco = encoder.transform(tmp_te[col].astype('category')) # 테스트 데이터 인코딩
enco_te = pd.concat([enco_te, _enco], axis=1)
# 훈련 데이터에서 학습한 인코더를 사용하여 테스트 데이터(tmp_te[col])를 인코딩
# 이미 학습된 인코더를 사용하기 때문에 transform만 사용
# ! 동일한 인코딩 방식을 유지하기 위해서
# 인코딩된 결과는 enco_te에 열 방향으로 추가
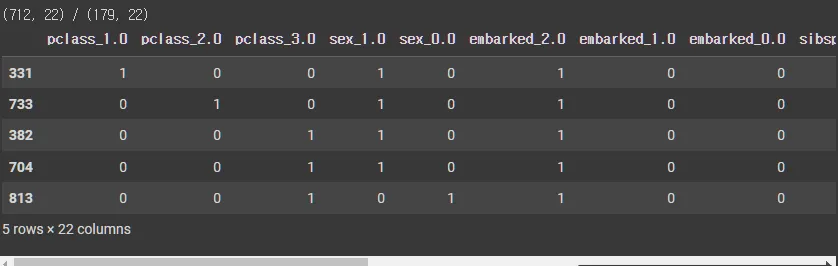
print(f'{enco_tr.shape} / {enco_te.shape}')
enco_tr.head()
Python
복사
여러 데이터프레임의 인덱스 재설정
features_tr = features_tr.reset_index(drop=True)
features_te = features_te.reset_index(drop=True)
enco_tr = enco_tr.reset_index(drop=True)
enco_te = enco_te.reset_index(drop=True)
# reset_index(drop=True) : 각 데이터프레임의 인덱스를 재설정
# drop=True : 기존의 인덱스를 삭제하고, 0부터 시작하는 새로운 연속적인 인덱스를 생성
# 즉, 인덱스 정보가 데이터프레임에 남지 않음
# features_tr, features_te, enco_tr, enco_te 네 개의 데이터프레임에 대해 모두 인덱스를 재설정
features_tr.shape, enco_tr.shape
# ((712, 2), (712, 22))
Python
복사
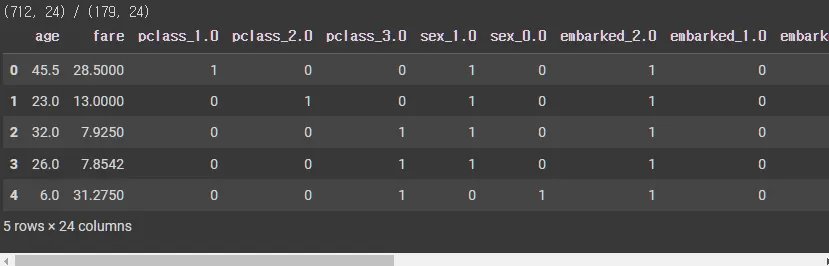
features_tr와 enco_tr, features_te와 enco_te 데이터프레임을 병합하여 새로운 데이터프레임 df_tr와 df_te를 생성
df_tr = pd.concat([features_tr,enco_tr],axis=1).reset_index(drop=True)
df_te = pd.concat([features_te,enco_te],axis=1).reset_index(drop=True)
# pd.concat([features_tr, enco_tr], axis=1)는 features_tr과 enco_tr 데이터프레임을 열(axis=1) 기준으로 병합
# features_te와 enco_te도 동일하게 병합
# reset_index(drop=True)는 병합 후 인덱스를 재설정하고, 기존의 인덱스를 제거하여 새로운 인덱스를 0부터 시작하도록 만든다.
# 결과
# df_tr와 df_te라는 두 개의 새로운 데이터프레임을 생성
# 각각 features_tr + enco_tr, features_te + enco_te의 조합
print(f'{df_tr.shape} / {df_te.shape}')
df_tr.head()
Python
복사
의사결정나무(Decision Tree) 분류 모델을 학습하고, 학습 데이터(df_tr)와 테스트 데이터(df_te)에서의 정확도(accuracy)를 평가
model = DecisionTreeClassifier(random_state=SEED)
# DecisionTreeClassifier : 사이킷런에서 제공하는 의사결정나무 분류기
# random_state=SEED는 모델의 학습 결과를 재현 가능하게 만드는 옵션
# 특정 시드(SEED)를 지정하면, 동일한 데이터와 파라미터로 학습할 때 항상 동일한 결과가 도출
# 이 줄에서는 의사결정나무 분류 모델 객체를 생성
model.fit(df_tr,target_tr)
# fit(df_tr, target_tr) : 모델을 학습시키는 과정
# df_tr : 학습에 사용될 특징(feature) 데이터
# target_tr : 그에 대응하는 레이블(target) 데이터
tr_score = model.score(df_tr,target_tr)
# score(df_tr, target_tr) 메서드는 학습 데이터에서 모델의 정확도를 계산
te_score = model.score(df_te,target_te)
# 테스트 데이터 df_te와 해당하는 레이블 target_te를 사용하여 모델의 정확도를 계산
tr_score, te_score
# (0.9803370786516854, 0.776536312849162)
Python
복사
