



들어가며
•
해당 시리즈는  linkedinBhavishya Pandit on LinkedIn: 25 Types of RAG | 142 comments에서 각 25가지의 RAG 파이프라인에 대한 동작 및 목표를 좀 더 이해하기 쉽도록 관련 논문을 직접 리뷰하고 추가 레퍼런스를 조사하여 구체적인 설명을 추가한 포스트이다.
linkedinBhavishya Pandit on LinkedIn: 25 Types of RAG | 142 comments에서 각 25가지의 RAG 파이프라인에 대한 동작 및 목표를 좀 더 이해하기 쉽도록 관련 논문을 직접 리뷰하고 추가 레퍼런스를 조사하여 구체적인 설명을 추가한 포스트이다.
linkedinBhavishya Pandit on LinkedIn: 25 Types of RAG | 142 comments에서 각 25가지의 RAG 파이프라인에 대한 동작 및 목표를 좀 더 이해하기 쉽도록 관련 논문을 직접 리뷰하고 추가 레퍼런스를 조사하여 구체적인 설명을 추가한 포스트이다.•
해당 RAG를 사용하기 위해서 각 파이프라인이 어떤 목표를 가지고 사용되는 지 명확히 이해하자.
•
그런 다음 실제로 프로젝트에서 핵심 동작과정을 참고하여 다양한 방면으로 각 서비스에 맞춰 활용/개량시키는 용도로 봐주면 제대로 본거다!
참고하기
•
하단 포스트는 제일 기본적으로 사용되는 RAG에 대한 컨퍼런스 노트로 작성된 글이다.

•
들어가기에 앞서서 RAG에 대한 지식이 적다면 간단하게 훑고 본 시리즈를 보는 것을 추천한다.
•
1~5번까지의 내용은 위 포스트의 내용과 거의 동일하여 간략하게 설명한 것이니 읽다가 궁금한게 생긴다면 위 포스트를 읽고 넘어가자.
•
5번 이후 내용에는 깊은 이해가 필요한 부분이 어느정도 있어서 직접 해당 논문 리뷰를 진행한 것과 관련 레퍼런스를 참고한 것을 바탕으로 동작 원리나 수식에 대한 구체적인 설명이 동반된다.
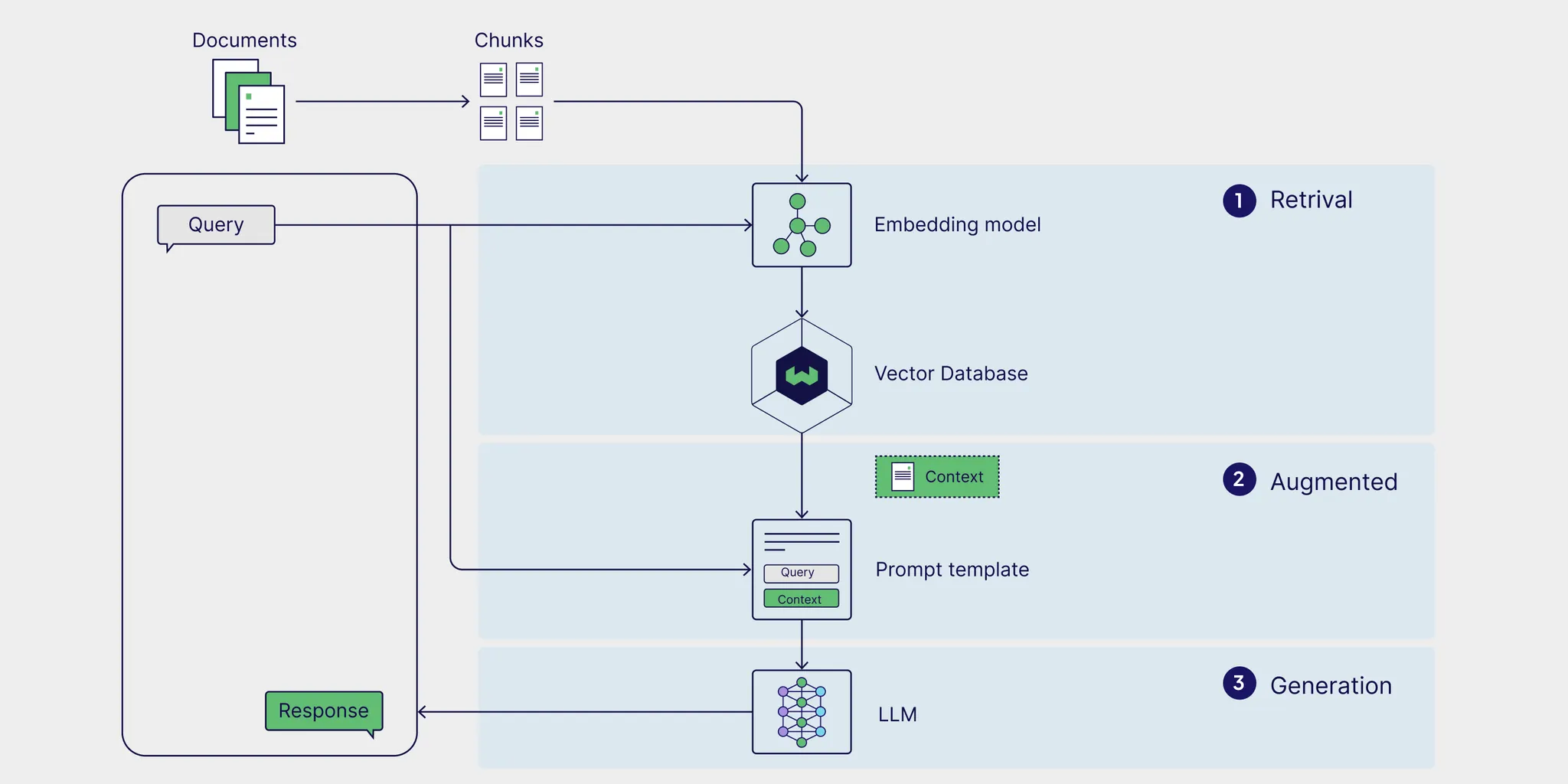
1. 표준(Standard) RAG
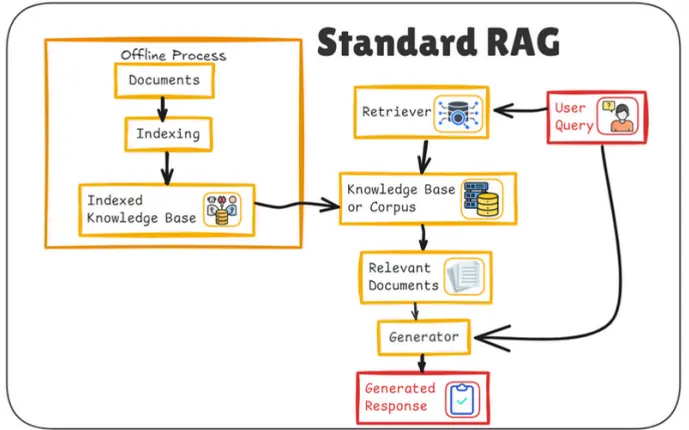
Standard RAG란?
•
표준 RAG는 검색-증강 생성의 약자
•
정보 검색과 대규모 언어 모델 사용이라는 두 가지 중요한 기술을 결합한 방법
•
많은 것을 알고 있을 뿐만 아니라 올바른 정보를 빠르게 찾아 질문에 정확하게 답할 수 있는 똑똑한 비서라고 생각하면 된다.
검색과 언어 모델의 결합
•
언어 모델 부분은 인간과 유사한 텍스트를 이해하고 생성할 수 있는 매우 발전된 로봇과 같다.
•
이 둘을 함께 사용하면 정확할 뿐만 아니라 질문하는 내용과도 관련이 있는 답변을 얻을 수 있다.
검색 부분은 시스템이 도서관에서 책을 검색하는 것과 같이 다양한 출처에서 정보를 조회할 수 있다는 것을 의미
목표
빠른 응답 시간
•
Standard RAG의 목표 중 하나는 1~2초 만에 답변을 제공하는 것
•
이는 가상 어시스턴트와 채팅할 때와 같이 실시간으로 사용하는 데 중요하다.
•
질문을 하고 답변을 받기 위해 오랜 시간을 기다려야 한다면 답답할 수 있다.
•
빠른 응답은 상호작용을 원활하고 효율적으로 만들어 준다.
답변 품질 향상
•
표준 RAG는 외부 데이터 소스를 사용하여 답변의 품질을 개선한다.
→ 즉, 이미 알고 있는 정보뿐만 아니라 다양한 곳에서 정보를 가져올 수 있다.
예를 들어 날씨에 대해 문의하면 날씨 웹 사이트를 확인하여 가장 정확한 최신 정보를 제공할 수 있다.
•
따라서 답변의 신뢰성과 유용성이 향상된다.
주요 동작
문서를 여러 조각으로 나누기 - 청킹(Chunking)
•
Standard RAG는 정보를 더 쉽게 찾을 수 있도록 큰 문서를 청크라고 하는 작은 조각으로 나눈다.
한 번에 큰 책을 읽으려고 한다고 상상해보면 굉장히 부담스럽다.
그래서 책을 작은 섹션으로 나누면 책에서 특정 장을 찾는 것처럼 특정 정보를 더 쉽게 빠르게 찾을 수 있다.
2. 교정(Corrective) RAG
Corrective RAG란?
•
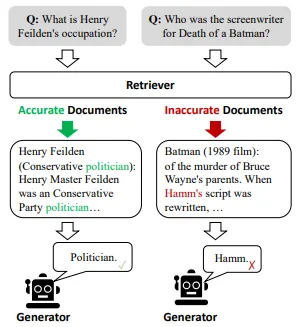
RAG 기반의 생성 모델에서 잘못된 검색 결과를 교정하고, 더 정확하고 신뢰할 수 있는 답변을 생성하기 위한 자체 교정 메커니즘을 도입한 모델
•
목표는 생성된 응답에서 오류를 찾아 수정하는 것이다.
교사가 학생의 숙제를 점검하고 오류를 수정하도록 도와주는 것과 같다고 생각하자.
•
플러그 앤 플레이 방식으로 다양한 RAG 기반 접근 방식과 원활하게 결합할 수 있다.
목표
높은 정밀도
•
Corrective RAG는 Standard RAG에서 실수를 수정하고 답변의 질을 높이기 위해 적극적으로 노력함으로써 정밀도를 개선시킨다.
•
사용자의 피드백을 활용하여 수정 프로세스를 개선시킨다.
웹 검색 확장
•
정적이고 제한된 코퍼스가 아닌, 웹 검색을 통해 추가적인 정보를 보충하여 지식의 다양성과 범위를 확장한다.
•
Corrective RAG는 검색된 문서에서 핵심 정보에 선택적으로 집중하고 관련 없는 정보를 걸러낼 수 있도록 분해 후 재구성 알고리즘이 설계되어 있다.
주요 동작
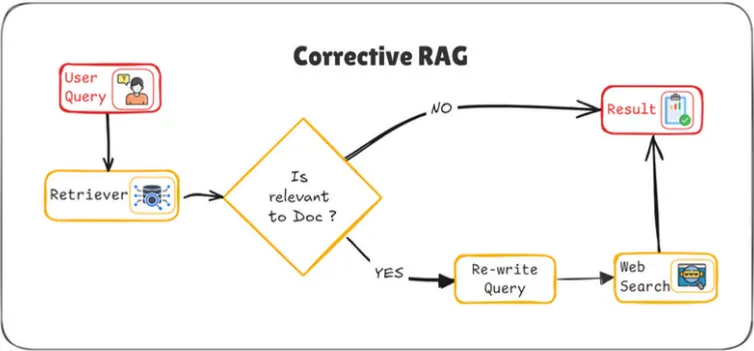
Re-write Query + Web Search
•
사용자 쿼리에 LLM을 한번 더 적용하여, 사용자가 알고자 하는 핵심 정보로 재작성하는 것
•
웹 검색은 정적 코퍼스에서 유효한 결과를 얻지 못한 경우 활용된다. 이 단계에서 검색 질의를 간단한 키워드 형태로 변환한 후 검색을 수행한다.
•
다시 쓰기-검색-읽기 접근 방식을 사용
•
재작성된 질의는 검색 API를 통해 적합한 정보를 가져온다.
행동 트리거(Action Trigger)
•
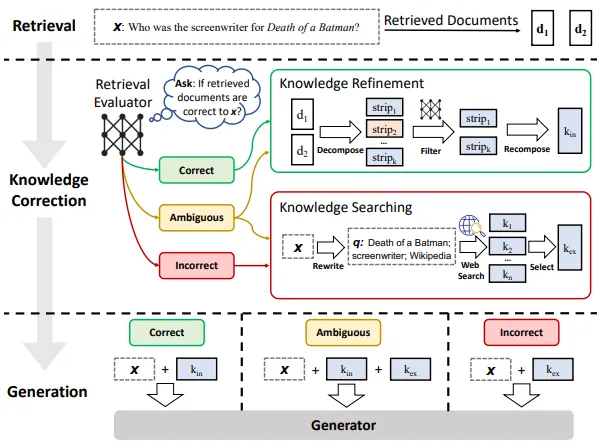
검색 평가 단계에서 계산된 관련성 점수를 기반으로 세 가지 행동을 트리거한다.
◦
Correct
▪
신뢰할 수 있는 검색 결과는 내부적으로 정제(refinement) 과정을 거친다.
▪
검색 문서에서 핵심 정보(knowledge strips)를 분리한 후 재구성하여 LLM에 전달한다.
◦
Incorrect
▪
검색 결과가 부정확하다고 판단될 경우, 기존 검색 결과를 폐기하고, 웹 검색을 수행하여 새로운 지식을 가져온다.
▪
웹 검색은 검색 질의를 재작성(query rewriting)하여 수행하며, 관련 정보를 정제한다.
◦
Ambiguous
▪
검색 결과가 모호한 경우, 내부 정제된 지식과 웹 검색 지식을 결합하여 더 강건한 답변을 생성한다.
Multiple Passes
•
시스템이 답을 여러 번 검토하는 것
이야기를 더 잘 이해하기 위해 이야기를 여러 번 읽는 것이라고 생각하면 된다.
•
검사할 때마다 실수를 찾아내고 답을 더 명확하고 정확하게 할 수 있는 방법을 찾아낸다.
3. 추론(Speculative) RAG
Speculative RAG란?
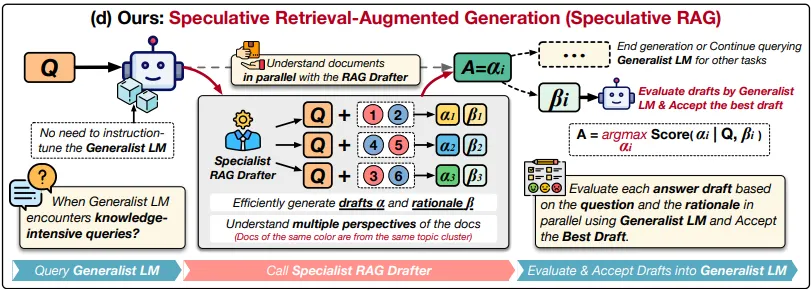
•
인공 지능에서 기계가 정보를 생성하고 검증하는 방식을 개선하기 위해 사용하는 방법
•
검색과 대규모 언어 모델을 결합하여 정확하고 문맥을 인식하는 응답을 제공한다.
◦
해당 접근 방식은 두 가지 유형의 모델, 즉 소규모 전문가 모델과 대규모 일반 모델을 결합한다.
목표
뛰어난 정확도
•
표준 RAG 시스템은 일반적으로 드래프팅과 검증 모두에 단일 모델을 사용하므로 실수가 발생하거나 응답의 정확도가 떨어질 수 있다.
•
Speculative RAG는 전문가 모델과 일반 모델 간에 작업을 구분하여 제공하는 정보의 정확도를 높힌다.
효율적인 처리
•
특수 모델을 사용하면 복잡한 작업을 줄일 수 있다.
→ 즉, 소규모 Specialist RAG Drafter는 빠른 초안 작성을 처리하는 반면 대규모 Generalist LLM은 더 복잡한 검증을 처리한다.
•
시스템은 작업을 분담함으로써 계산 부하를 줄여주는데, 이는 마치 무거운 배낭을 친구들과 나누어 들고 다니기 편하도록 하는 것과 같다.
주요 동작
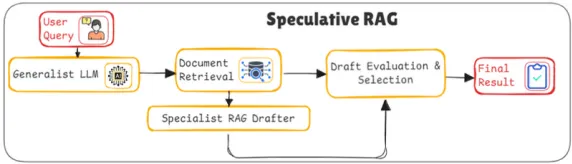
문서 검색 및 클러스터링 (Document Retrieval and Clustering)
•
사용자의 질문 가 주어지면, 검색 시스템이 관련 문서 집합 을 데이터베이스에서 검색한다.
•
검색된 문서들은 의미적 유사성(semantic similarity)을 기준으로 개의 클러스터 로 그룹화된다.
•
각 클러스터는 하나의 특정 주제를 반영하며, 이후 문서 서브셋 구성을 위한 기본 단위로 사용된다.
◦
각 클러스터에서 대표 문서를 무작위로 샘플링하여 개의 문서 서브셋 를 생성
병렬 초안 생성(Parallel Draft Generation)
•
MDrafter는 각각의 문서 서브셋 와 질문 를 기반으로 초안 와 근거 를 생성한다.
•
각 초안은 질문에 대한 잠정적인 응답이며, 근거는 이 초안이 문서 서브셋에 기반한 신뢰할 수 있는 정보임을 설명한다.
•
이 때, 각 문서 서브셋에 대해 초안 생성을 병렬로 수행하므로, 생성 속도가 크게 향상된다.
•
서로 다른 문서 서브셋을 사용함으로써 동일 질문에 대해 다양한 관점을 반영한 초안을 생성할 수 있다.
초안 평가 및 선택 (Draft Evaluation and Selection)
•
Generalist LLM은 MDrafter가 생성한 초안 와 근거 를 평가하고, 각 초안의 신뢰도를 점수화한다.
초안 및 근거의 신뢰도는 다음과 같이 계산된다.
•
: 근거가 질문과 문서 서브셋에 대해 얼마나 일관적인지를 나타냄.
•
: 초안 자체의 신뢰도를 평가.
•
최종적으로 가장 신뢰할 수 있는 초안을 선택하여 사용자에게 응답으로 제공한다.
•
가장 높은 점수를 가진 초안이 최종 응답으로 선택된다.
•
Generalist LLM은 MDrafter의 결과를 검증하며, 부정확하거나 불필요한 초안을 걸러내고 신뢰할 수 있는 최적의 답변만 선택한다.
4. Fusion RAG with Re-ranking
Fusion RAG란?
•
다중 검색 엔진의 결합과 재배열을 통해 검색 정확성과 응답 품질을 높이기 위해 설계된 RAG의 확장된 버전
•
기존 RAG와 달리 Fusion RAG는 Reciprocal Rank Fusion(RRF) 알고리즘을 활용하여 검색된 문서를 결합하고, 이를 바탕으로 최적의 순위를 재배치한다.
•
이는 문서의 개별 순위 평가, 순위 결합, 최종 응답 생성의 단계를 통해 수행된다.
다중 검색 방법(Retriever) 통합
•
두 가지 이상의 기술을 사용하여 정보를 찾는다.
예를 들어 키워드 검색, 시맨틱 검색 (단어의 의미를 이해함), 심지어 가장 관련성이 높은 정보를 예측할 수 있는 기계 학습 모델도 사용할 수 있다.
다중 데이터 소스 접근
•
여러 가지 유형의 데이터 또는 정보를 함께 활용하여 인공 지능 시스템을 구축하는 접근 방식 (Multi-modal)을 사용
•
데이터베이스, 웹 사이트, 문서, 심지어 사용자 제작 콘텐츠도 포함될 수 있다.
•
이미지, 동영상, 텍스트 등등의 다양한 유형의 데이터를 사용한다.
목표
응답 품질 향상
•
다양한 방법과 출처를 사용하는 목적은 답변의 질을 높이는 것
양질의 답변: 정확하고 관련성이 높으며 상세한 답변
예를 들어, 사용자가 기후 변화에 대해 질문하면 기후 변화가 무엇인지 설명할 뿐만 아니라 통계, 영향 및 가능한 해결책도 제공하는 좋은 답변이 될 수 있다.
종합 답변
•
다양한 데이터 입력을 활용하여 질문의 여러 측면을 포괄하는 답변을 제공할 수 있다.
•
시스템에서 단순히 짧은 답변을 제공하는 대신 주제를 심층적으로 설명할 수 있다.
•
검색 엔진 간 중복을 최소화하고, 여러 관점에서 정보를 수집함으로써 응답의 포괄성과 유용성을 증대한다.
시스템 복원력 향상
Resilience: 한 부품에 장애가 발생하더라도 시스템이 계속 정상적으로 작동할 수 있는 능력
•
하나의 정보 소스에만 의존하지 않기 때문에 한 소스를 사용할 수 없거나 잘못된 정보가 있는 경우에도 여전히 좋은 답을 제공할 수 있다.
•
한 가지 계획이 효과가 없을 경우 다른 계획으로 대체할 수 있다.
동적 검색 전략 (적응성)
•
시스템에서 질문의 컨텍스트를 기반으로 정보를 검색하는 방법을 변경할 수 있다.
•
사용자가 매우 구체적인 질문을 하는 경우 시스템은 보다 집중적인 검색 방법을 사용할 수 있다.
•
질문이 광범위하면 광범위한 검색 방식을 사용할 수 있다.
주요 동작
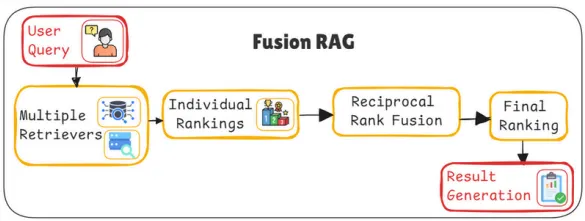
다중 검색기(Multiple Retrievers)
•
Fusion RAG는 하나의 검색 엔진이 아닌 다중 검색 엔진을 사용한다.
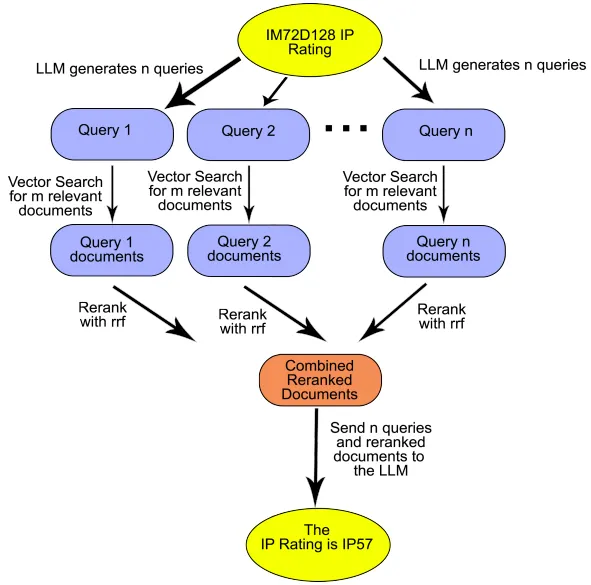
Diagram illustrating the high level process of RAG-Fusion starting with the original query ”IM72D128 IP Rating”
◦
사용자 입력 질의 를 다중 검색 엔진에 전달한다.
◦
각 검색 엔진에서 독립적으로 관련 문서 집합 을 검색한다.
•
여러 검색기를 동시에 사용해 사용자 쿼리에 맞는 정보를 각각의 데이터 소스에서 수집
•
사용자 쿼리가 들어오면 시스템은 여러 검색 엔진(혹은 검색 알고리즘)을 통해 관련 문서를 검색한다.
•
이는 서로 다른 검색 알고리즘 또는 인덱스 구조를 가진 검색 엔진에서 질의에 대해 독립적으로 문서를 검색함으로써, 더 많은 정보를 포착하고 검색 다양성을 확보한다.
개별 순위 평가(Individual Rankings)
•
각 검색 엔진에서 반환된 문서들은 개별적으로 순위화된다.
◦
여기서 순위는 검색된 문서가 질의에 얼마나 관련성이 높은지를 나타내며, 각 문서에 고유한 점수가 부여된다.
◦
개별 검색 엔진에서 문서 에 대한 점수는 다음과 같다.
▪
: 검색 엔진 R_i에서 문서 d의 순위.
▪
: 정규화 상수, 낮은 순위에 대한 가중치를 조정.
•
다중 검색기를 통해 수집된 정보들은 각각의 검색기 기준에 따라 순위가 매겨진다.
한 검색기는 텍스트 유사도를 기준으로 순위를 매기고, 다른 검색기는 키워드 매칭 빈도를 기준으로 순위를 매기는 방식이다.
•
검색기마다 우선 순위 기준이 다르므로 같은 결과라도 다른 검색기에서는 다른 순위를 가질 수 있다.
상호 순위 융합 (Reciprocal Rank Fusion, RRF)
•
각 검색기의 순위를 반영, 개별 검색기의 순위 점수를 역순으로 합산하여 최종 점수를 산출하는 방식
◦
다중 검색 엔진에서 개별적으로 평가된 순위를 RRF 알고리즘을 통해 결합하여 최종 문서 순위를 생성한다.
RRF 알고리즘
•
: 문서 의 최종 점수.
•
: 참여한 검색 엔진의 개수.
•
특정 결과가 여러 검색기에서 상위에 위치하면 해당 결과의 최종 점수는 높아지고, 반대로 특정 검색기에서만 높은 순위를 가지는 결과는 최종 점수에 덜 반영된다.
5. Agentic RAG
Agentic RAG란?
•
정보를 빠르고 효과적으로 찾고 사용하는 방법을 개선하기 위해 설계된 시스템
•
필요한 답변을 실시간으로 얻을 수 있도록 도와주는 스마트 어시스턴트라고 생각하자.
실시간 전략 조정을 위한 적응형 에이전트
•
이들은 마치 현재 상황에 따라 접근 방식을 바꿀 수 있는 작은 조력자와 같다.
질문을 했는데 상담원이 더 나은 답변을 제공하기 위해 다른 정보를 찾아야 한다는 것을 알게 되면 즉시 전략을 조정할 수 있다.
→ 즉, 요구 사항에 더 효과적이고 신속하게 대응할 수 있다는 것이다.
간편한 통합을 위한 모듈식 설계
•
기존 RAG는 순차적인 구조를 가진다.
◦
순진한 RAG 파이프라인은 외부 지식 소스를 하나만 고려한다.
◦
그러나 일부 솔루션은 두 개의 외부 지식 소스를 필요로 할 수 있으며, 일부 솔루션은 웹 검색과 같은 외부 도구 및 API를 필요로 할 수 있다.
◦
이들은 원샷 솔루션으로, 컨텍스트가 한 번만 검색된다는 것을 의미한다. 검색된 컨텍스트의 품질에 대한 추론이나 검증은 없다.
•
하지만 Agentic RAG의 설계는 기본적으로 모듈식이다.
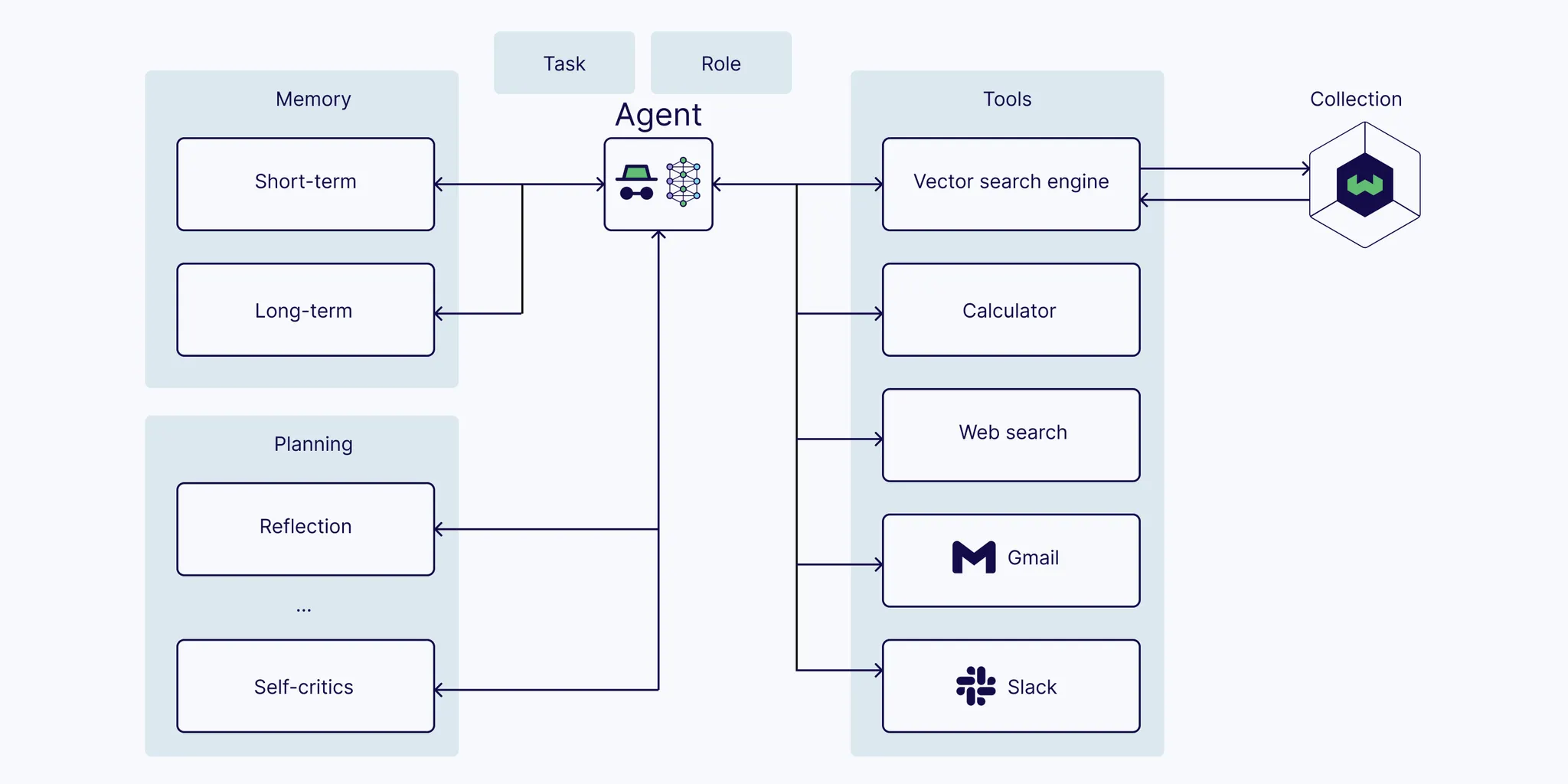
◦
즉, 함께 작동할 수 있는 별도의 부품으로 제작된다.
목표
사용자 의도 해석
•
질문을 할 때 실제로 원하는 것이 무엇인지 이해할 수 있다는 것
'최고의 피자'를 입력하면 시스템은 사용자가 근처에 있는 최고의 피자 가게를 찾고 있는지, 최고의 피자 레시피를 찾고 있는지 등을 알아야 한다.
•
시스템에서 사용자의 의도를 정확히 이해하면 관련성이 높고 신뢰할 수 있는 응답을 제공할 수 있다.
병렬 처리 향상
•
Agentic RAG는 동시에 여러 에이전트를 실행할 수 있다.
•
이는 여러 어시스턴트가 서로 다른 작업을 동시에 처리하는 것과 같다.
한 상담원이 최고의 피자 가게를 찾고 있는 동안 다른 상담원은 피자 레시피를 찾을 수 있다.
•
이러한 동시 작업 기능은 특히 많은 정보가 필요한 복잡한 질문을 처리할 때 시스템 성능을 향상시키는 데 도움이 된다.
주요 동작
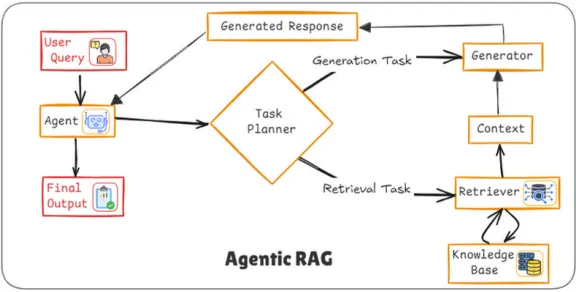
에이전트 (Agent)
•
에이전트는 사용자 쿼리를 받고, 이를 기반으로 어떤 정보가 필요한지와 어떤 방식으로 처리할지를 결정한다.
•
이를 위해 Task Planner(작업 계획자)에게 작업을 전달하며, 적절한 검색 및 생성 전략을 세운다.
작업 계획자 (Task Planner)
•
Task Planner는 사용자 쿼리에 맞는 정보 생성 또는 검색 작업을 계획한다.
•
여기서 작업은 두 가지로 나뉜다.
◦
Generation Task: 새로운 응답을 생성해야 하는 경우.
▪
생성기는 Task Planner에서 전달된 정보를 바탕으로 최종 응답의 일부 또는 전체 내용을 생성한다.
▪
주로 텍스트 생성 모델을 사용하여 응답을 생성하며, Context(문맥)을 참고하여 사용자 쿼리에 맞는 정보를 만든다.
◦
Retrieval Task: 기존 지식 기반에서 정보를 검색해야 하는 경우.
▪
검색기는 사용자가 요청한 정보와 일치하는 데이터를 Knowledge Base(지식 기반)에서 검색한다.
▪
이 정보는 사용자가 요청한 답변의 근거로 사용되며, 필요한 경우 Context에 전달되어 응답 생성에 활용된다.
•
Task Planner는 복잡한 작업을 더 세분화하여 효율적으로 처리할 수 있도록 돕는다.
단일/다중 에이전트 RAG
단일 에이전트 RAG(라우터)
•
라우터는 가장 단순한 형태의 에이전트 RAG이다.
-dd2f933fca457bcbf3864ec0df69740e.png&blockId=14200c82-b138-8081-832e-fb32cd908b80)
→ 최소 두 개의 외부 지식 소스가 있으며 에이전트가 어느 소스에서 추가 컨텍스트를 검색할지 결정한다.
•
그러나 외부 지식 소스는 (벡터) 데이터베이스로 제한될 필요는 없다.
•
도구에서 추가 정보를 검색할 수도 있다.
웹 검색을 수행하거나 API를 사용하여 Slack 채널이나 이메일 계정에서 추가 정보를 검색할 수 있다.
다중 에이전트 RAG 시스템
•
위에서 본 단일 에이전트 시스템은 추론, 검색 및 답변 생성을 하나로 하는 단 하나의 에이전트로 제한되기 때문에 한계가 있다.
•
따라서 여러 에이전트를 다중 에이전트 RAG 애플리케이션으로 연결하는 것이 더 낫다.
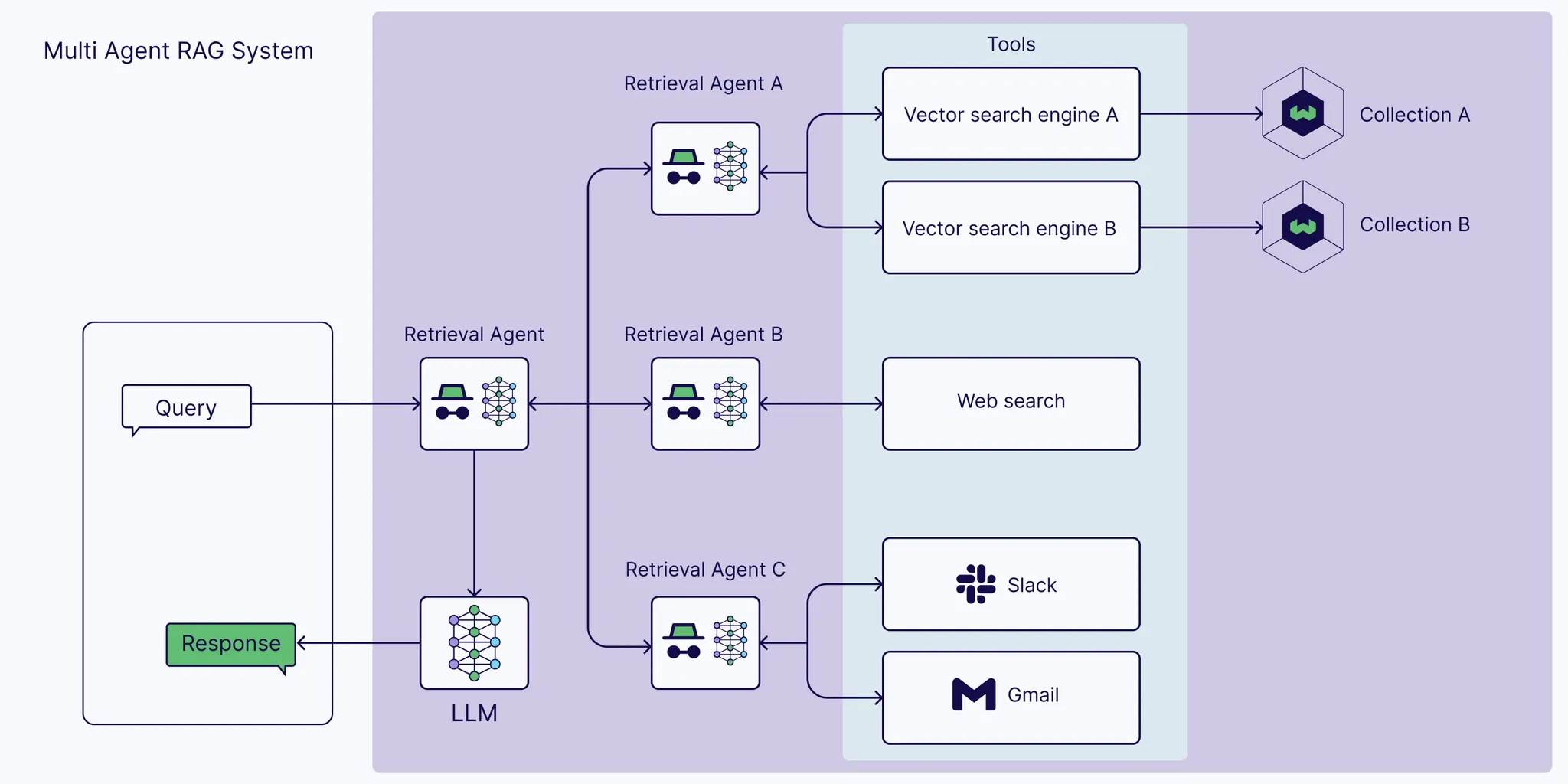
여러 전문 검색 에이전트 간에 정보 검색을 조정하는 마스터 에이전트가 있고, 한 에이전트는 독점적인 내부 데이터 소스에서 정보를 검색할 수 있다. 그리고 다른 에이전트는 이메일이나 채팅과 같은 개인 계정에서 정보를 검색하는 데 특화될 수 있다. 또 다른 에이전트는 웹 검색에서 공개 정보를 검색하는 데 특화될 수도 있다.
이렇듯 적절하게 에이전트 모듈을 배치하여 각 용도에 맞춰서 적절히 변화시킬 수 있는 장점을 가지고 있다!
